Oracle Application Express(APEX)19.2 正式发布了!

Oracle Application Express(APEX)19.2正式发布了!Oracle APEX 是市场领先的企业级低代码开发平台,您可以仅使用浏览器来设计、开发和部署漂亮、响应迅速、数据驱动的桌面和移动应用程序。APEX 19.2引入了许多令人兴奋的新功能和强大的数据驱动组件,以帮助提供功能丰富且现代的用户体验。
Oracle Application Express(APEX)19.2正式发布了!Oracle APEX 是市场领先的企业级低代码开发平台,您可以仅使用浏览器来设计、开发和部署漂亮、响应迅速、数据驱动的桌面和移动应用程序。APEX 19.2引入了许多令人兴奋的新功能和强大的数据驱动组件,以帮助提供功能丰富且现代的用户体验。

以下是截止至 2019.10.31收集的 Oracle APEX 最新博文,完整博文列表请移步这里:Oracle APEX Evangelion(EVA 补完计划)
常规APEX博文整理:
2019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.102019.092019.092019.092019.082019.082019.082019.082019.082019.082019.082019.072019.072019.072019.072019.072019.062019.052019.042019.042018.052017.032017.03
Kubernetes默认的健康检查是监控容器的ENTRYPOINT执行的程序是否正常(返回0),可以添加自定义健康检查以便符合我们真实需求。
当kill掉容器ENTRYPOINT执行的进程时,容器会被终止,k8s会尝试自动重启该容器。


Jenkins是一款开源 CI&CD 软件,用于自动化各种任务,包括构建、测试和部署软件。Jenkins 支持各种运行方式,可通过系统包、Docker 或者通过一个独立的 Java 程序。
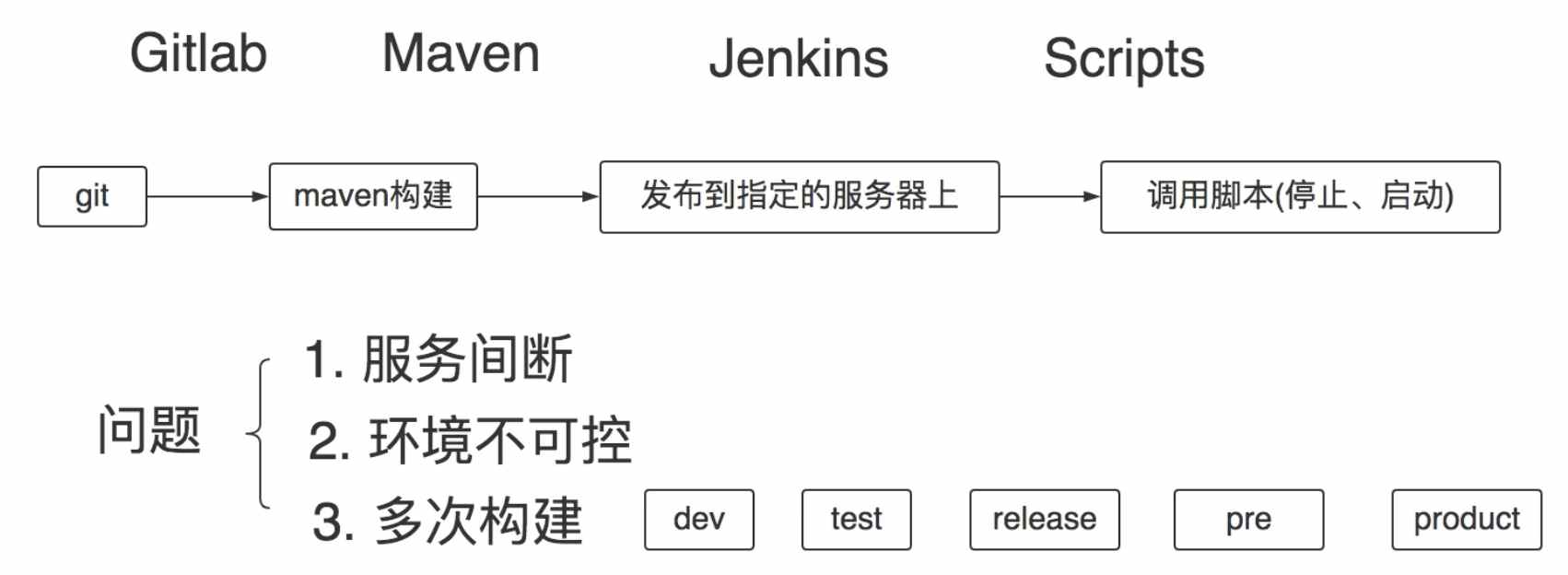
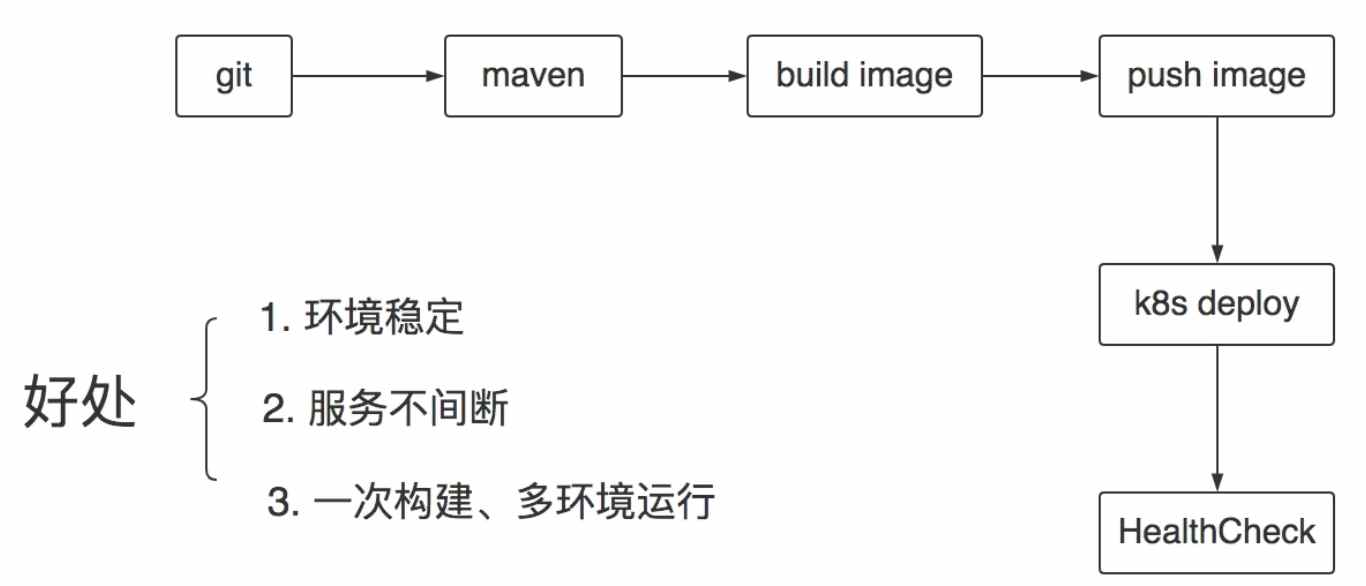

本文梳理不同Java应用如何迁移到k8s。

Harbor 是一个用于存储和分发Docker镜像的企业级Registry服务器,通过添加一些企业必需的功能特性,例如安全、标识和管理等,扩展了开源Docker Distribution。
作为一个企业级私有Registry服务器,Harbor提供了更好的性能和安全。提升用户使用Registry构建和运行环境传输镜像的效率。
Harbor支持安装在多个Registry节点的镜像资源复制,镜像全部保存在私有Registry中,确保数据和知识产权在公司内部网络中管控。
另外,Harbor也提供了高级的安全特性,诸如用户管理,访问控制和活动审计等。
- 基于角色的访问控制:用户与Docker镜像仓库通过“项目”进行组织管理,一个用户可以对多个镜像仓库在同一命名空间(project)里有不同的权限。
- 镜像复制:镜像可以在多个Registry实例中复制(同步)。尤其适合于负载均衡,高可用,混合云和多云的场景。
- 图形化用户界面:用户可以通过浏览器来浏览,检索当前Docker镜像仓库,管理项目和命名空间。
- AD/LDAP 支持:Harbor可以集成企业内部已有的AD/LDAP,用于鉴权认证管理。
- 审计管理:所有针对镜像仓库的操作都可以被记录追溯,用于审计管理。
- 国际化:已拥有英文、中文、德文、日文和俄文的本地化版本。更多的语言将会添加进来。
- RESTful API:RESTful API 提供给管理员对于Harbor更多的操控, 使得与其它管理软件集成变得更容易。
- 部署简单:提供在线和离线两种安装工具, 也可以安装到vSphere平台(OVA方式)
虚拟设备。

本文是钢哥 Oracle Cloud 系列文章第三篇,Oracle Cloud系列文章列表如下:
CLI是一种命令行工具,允许你通过命令行来访问Oracle Cloud的可用服务。CLI提供与控制台相同的核心功能,以及其他命令。有关更多关于CLI的介绍,可以访问这里;
1 | bash -c "$(curl -L https://raw.githubusercontent.com/oracle/oci-cli/master/scripts/install/install.sh)" |


