Kubernetes学习笔记(6):健康检查 & 调度 & 部署

Kubernetes默认的健康检查是监控容器的ENTRYPOINT执行的程序是否正常(返回0),可以添加自定义健康检查以便符合我们真实需求。
当kill掉容器ENTRYPOINT执行的进程时,容器会被终止,k8s会尝试自动重启该容器。
k8s健康检查
cmd检查方式
web-dev-cmd.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
livenessProbe:
exec:
command:
- /bin/sh
- -c
- ps -ef|grep java|grep -v grep
initialDelaySeconds: 10
periodSeconds: 10
failureThreshold: 2
successThreshold: 1
timeoutSeconds: 5
这里主要关注
livenessProbe节点。可以看到这里通过shell脚本来监控java服务是否正常。
initialDelaySeconds: 检查前等待时间periodSeconds: 检查间隔时间failureThreshold: 失败次数(阈值)successThreshold: 成功次数(阈值)timeoutSeconds: 超时时间
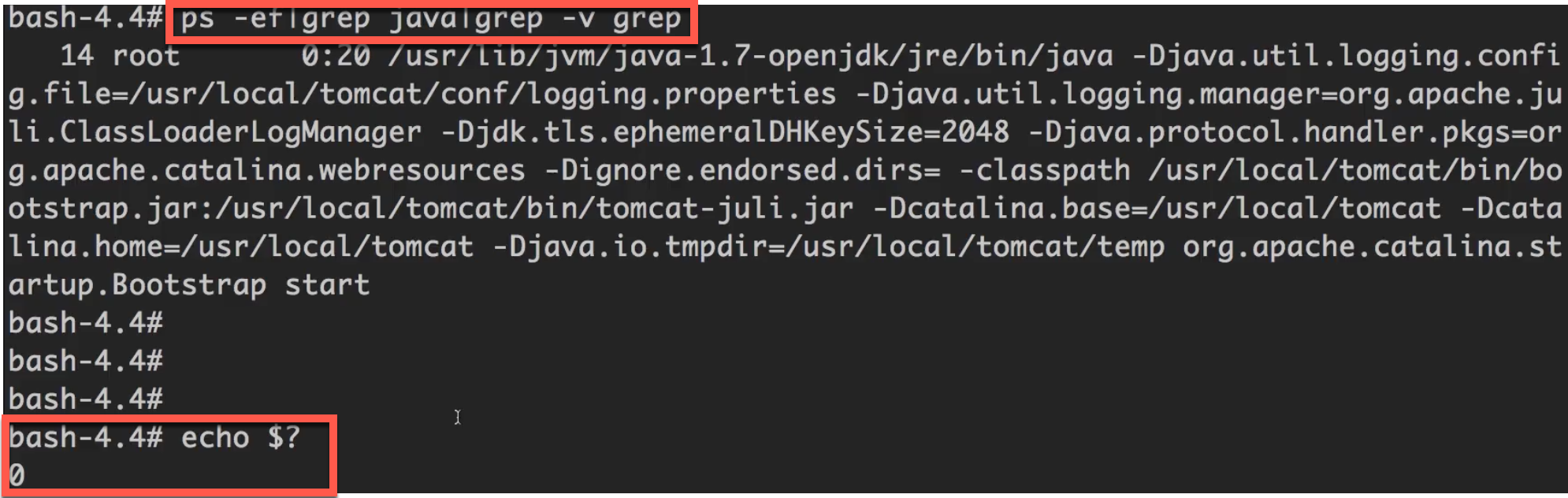
我们可以进到docker容器中,查看该shell健康检查命令执行的效果。
可以先执行该命令,然后用echo $?查看返回的结果,预期是0。
http检查方式
web-dev-http.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
livenessProbe:
httpGet:
path: /examples/index.html
port: 8080
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 5
failureThreshold: 2
successThreshold: 1
timeoutSeconds: 5
这里重点关注
livenessProbe节点,可以看到这次是监控http下的8080端口,看是否可以正常访问/examples/index.html这个页面。如果可以,则代表容器是健康的。
注意:如果
initialDelaySeconds或failureThreshold参数设置得过小,则可能导致容器还没启动完就被判断成异常而被反复重启。
tcp检查方式
web-dev-tcp.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 2
successThreshold: 1
timeoutSeconds: 5
通过监控TCP端口来实现健康检查,这里监控的是8080端口。
优化健康检查
我们发现,当容器一旦启动了(端口ok),即使还没启动好,k8s还是会将它暴露给前端,这时候如果访问,肯定是不能工作的。我们可以简单地修改yaml文件,添加
readinessProbe节点,这样就可以完美解决这个问题了。
livenessProbe: 负责告诉k8s什么时候需要重启;readinessProbe: 负责告诉k8s什么时候服务准备好了,可以对外暴露;
修改后的web-dev-tcp.yaml文件内容如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 2
successThreshold: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /examples/index.html
port: 8080
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 2
successThreshold: 1
timeoutSeconds: 5
注:web服务一般会采用
http的方式监控。
健康检查最佳实践
当某些服务不正常时的处理方法:
- 如果不是频繁发生的:调节livenessProbe参数,比如将等待时间增大,看问题是否缓解;
- 如果问题频繁发生:将livenessProbe执行的
监控脚本改成总是成功的,这样容器就不会被重启了,这样有助于分析具体问题的原因;
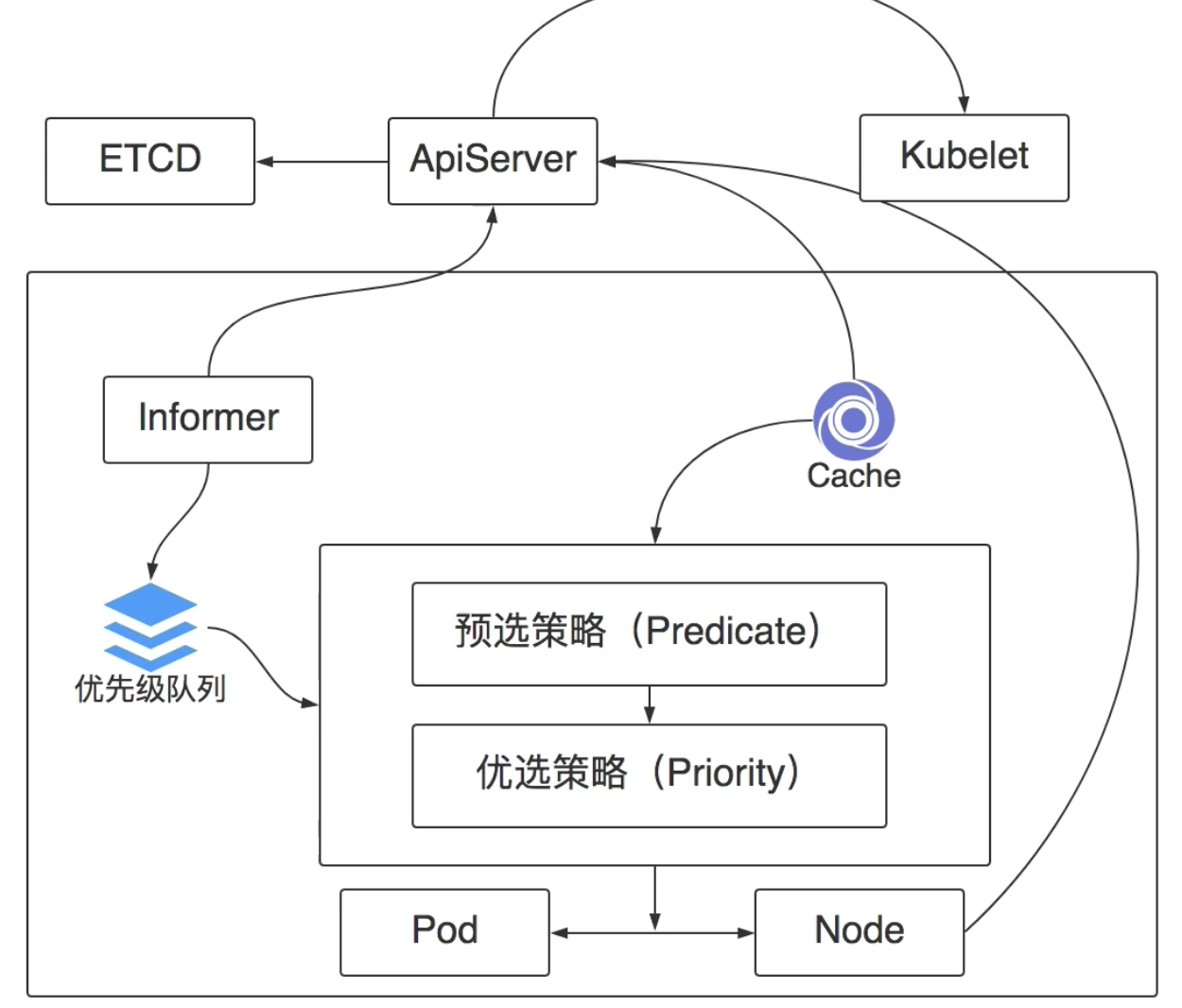
k8s调度策略
k8s的调度逻辑流程图。
节点(Node)亲和性(nodeAffinity)
web-dev-node.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo-node
namespace: dev
spec:
selector:
matchLabels:
app: web-demo-node
replicas: 1
template:
metadata:
labels:
app: web-demo-node
spec:
containers:
- name: web-demo-node
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: NotIn
values:
- ssd
这里重点关注
affinity.nodeAffinity节点。
requiredDuringSchedulingIgnoredDuringExecution: 必须满足的条件;如果条件没有满足,则k8s没有办法调度,容器会始终处于Pending状态;preferredDuringSchedulingIgnoredDuringExecution: 推荐条件,没有匹配也没关系;
Pod亲和性
web-dev-pod.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo-pod
namespace: dev
spec:
selector:
matchLabels:
app: web-demo-pod
replicas: 1
template:
metadata:
labels:
app: web-demo-pod
spec:
containers:
- name: web-demo-pod
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-demo
topologyKey: kubernetes.io/hostname
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-demo-node
topologyKey: kubernetes.io/hostname
podAffinity: 指明了当前这个deployment倾向于跟带有web-demo标签的deployment放在同一个节点上运行(topologyKey: kubernetes.io/hostname)
污点 & 污点容忍
可以在node上标记上污点,如果pod没有指明污点容忍,则不会被调度到这个node上。
通过taint关键字可以给node打污点。1
kubectl taint nodes <节点名> gpu=true:NoSchedule
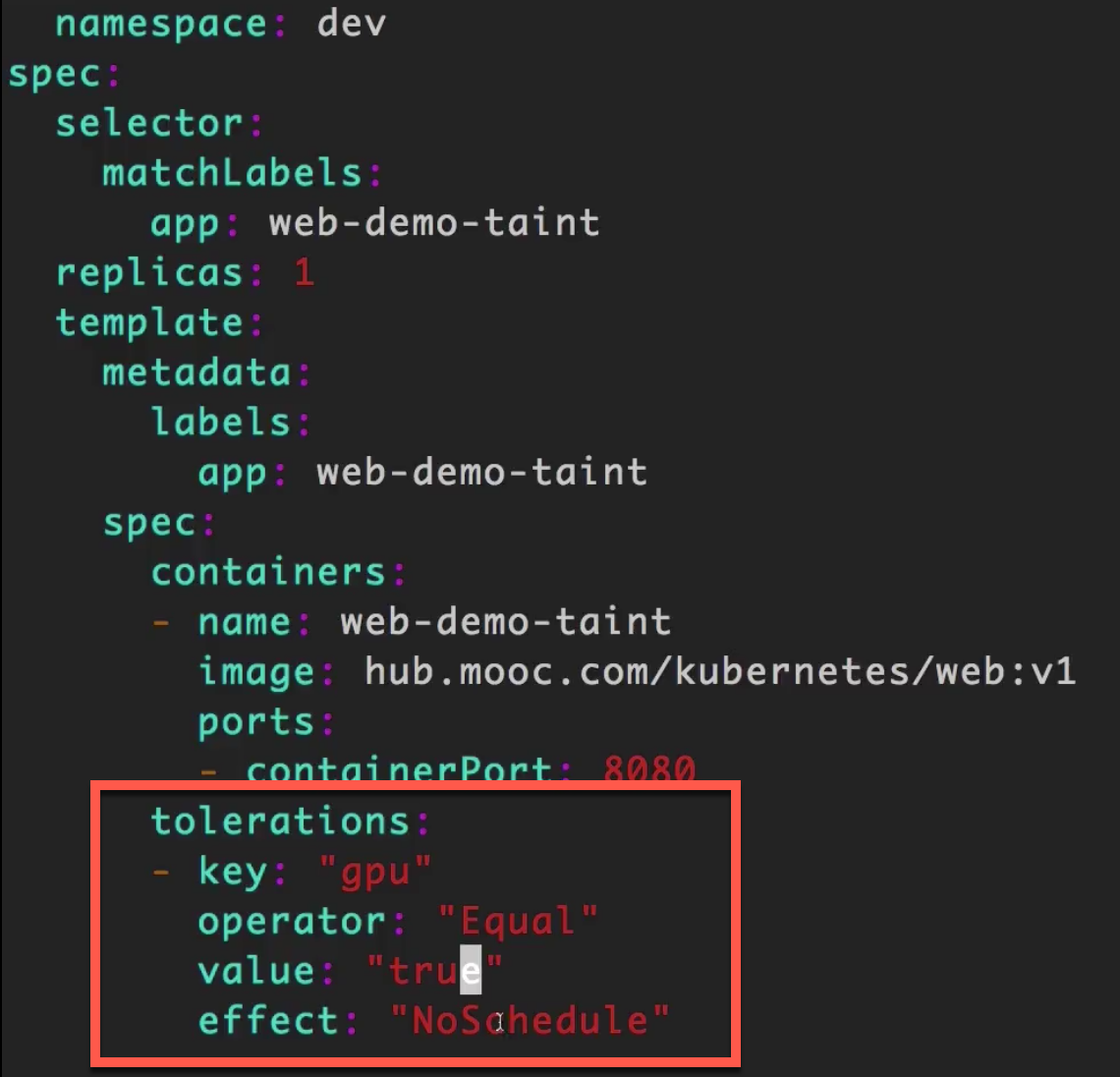
配置web-dev-taint.yaml文件,添加污点容忍。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo-taint
namespace: dev
spec:
selector:
matchLabels:
app: web-demo-taint
replicas: 1
template:
metadata:
labels:
app: web-demo-taint
spec:
containers:
- name: web-demo-taint
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
从配置中可以看到,我们添加了一个
tolerations节点,并配置了相关参数,以匹配之前配置的污点node,这样k8s就可以将deployment调度到这个污点node上了。
部署策略实践
K8s支持的部署策略:
- 滚动更新(Rolling Update)
- 重建(Recreate)
利用k8s的labelSelector还可以实现:
- 蓝绿部署
- 金丝雀部署
重建部署(Recreate)
web-recreate.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-recreate
namespace: dev
spec:
strategy:
type: Recreate
selector:
matchLabels:
app: web-recreate
replicas: 2
template:
metadata:
labels:
app: web-recreate
spec:
containers:
- name: web-recreate
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 2
successThreshold: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /examples/index.html
port: 8080
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 5
failureThreshold: 1
successThreshold: 1
timeoutSeconds: 5
#service
apiVersion: v1
kind: Service
metadata:
name: web-recreate
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: web-recreate
type: ClusterIP
#ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web-recreate
namespace: dev
spec:
rules:
- host: web-recreate.mooc.com
http:
paths:
- path: /
backend:
serviceName: web-recreate
servicePort: 80
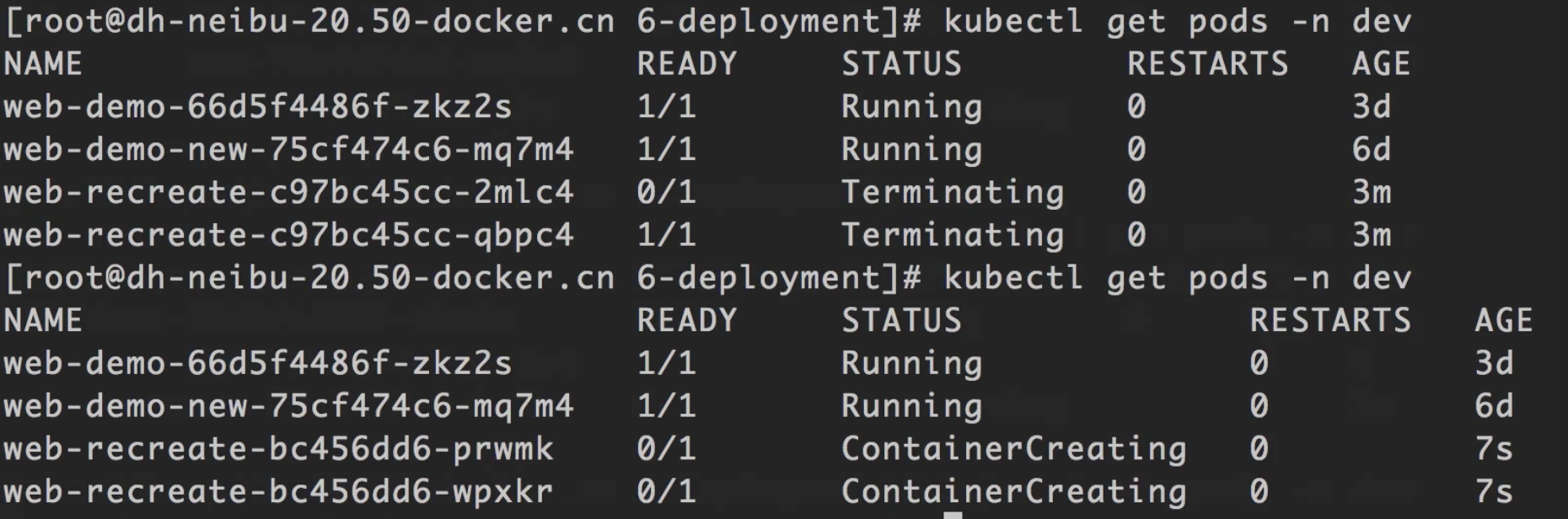
可以看到这个配置文件里有一个
strategy.type: Recreate, 配置了这个选项后,一旦任何时候重新部署应用,k8s都会先将所有该应用的实例停掉,然后再重新启动一批实例,而不像rolling update那样边停边起。
带来的问题:服务会间断。
滚动更新(Rolling Update)
web-rollingupdate.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-rollingupdate
namespace: dev
spec:
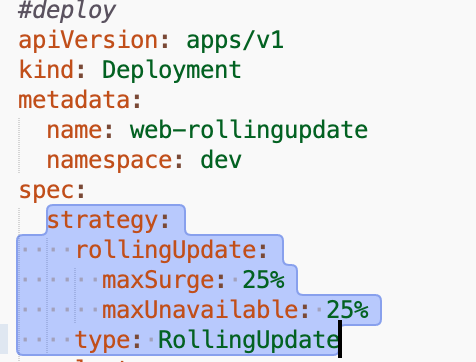
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
selector:
matchLabels:
app: web-rollingupdate
replicas: 2
template:
metadata:
labels:
app: web-rollingupdate
spec:
containers:
- name: web-rollingupdate
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
resources:
requests:
memory: 1024Mi
cpu: 500m
limits:
memory: 2048Mi
cpu: 2000m
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 3
successThreshold: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /hello?name=test
port: 8080
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 1
successThreshold: 1
timeoutSeconds: 5
#service
apiVersion: v1
kind: Service
metadata:
name: web-rollingupdate
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: web-rollingupdate
type: ClusterIP
#ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web-rollingupdate
namespace: dev
spec:
rules:
- host: web-rollingupdate.mooc.com
http:
paths:
- path: /
backend:
serviceName: web-rollingupdate
servicePort: 80
对于滚动部署(
rollingUpdate)来说,可以配置maxSurge(最大超出实例比例)和maxUnavailable(最大不可用实例),k8s有默认的滚动更新配置。
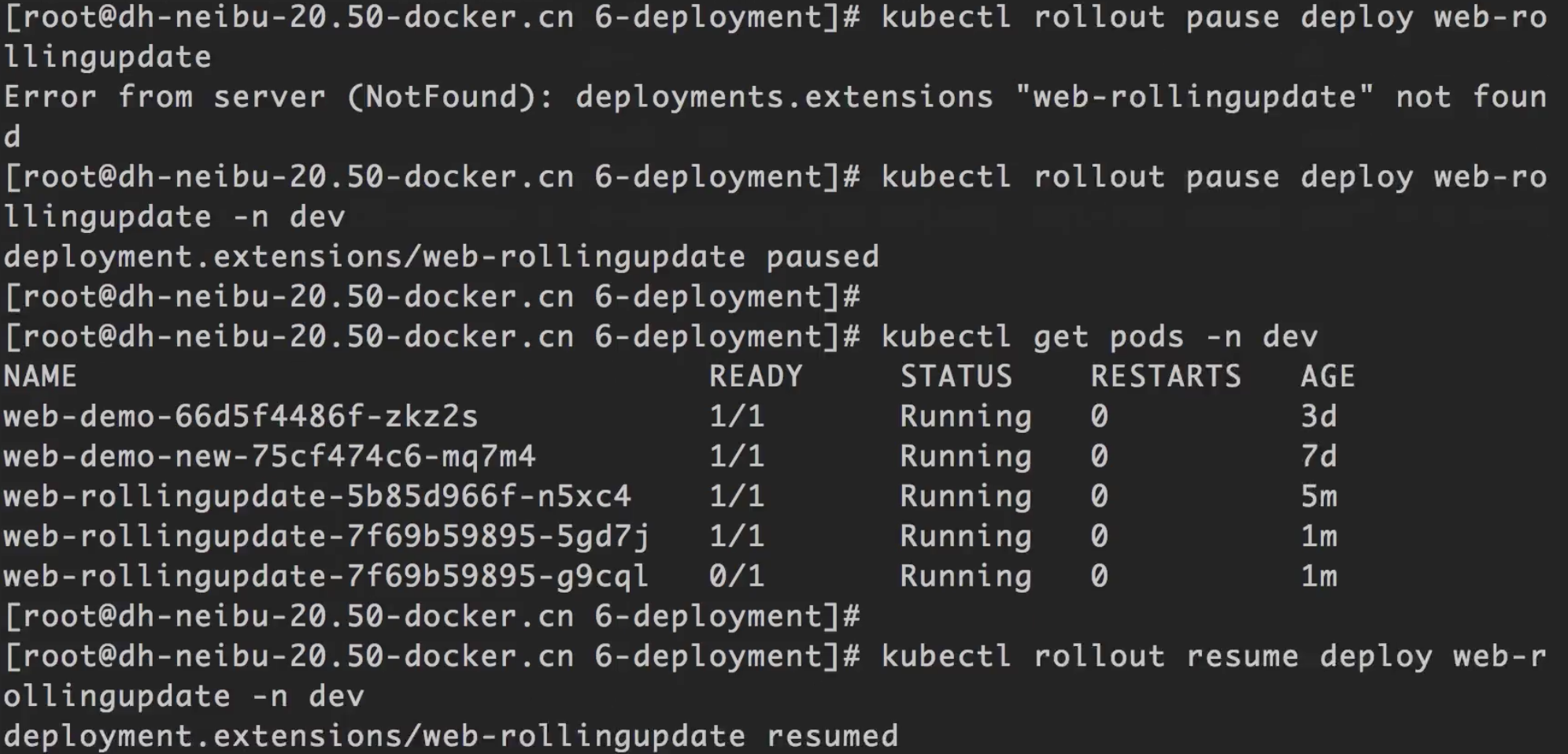
暂停更新
通过rollout pause关键字可以暂停部署。1
kubectl rollout pause deploy <deployment名> -n <namespace名>
恢复更新
通过rollout resume关键字可以恢复暂停的部署。1
kubectl rollout resume deploy <deployment名> -n <namespace名>
回滚更新
通过rollout undo关键字可以恢复暂停的部署。1
kubectl rollout undo deploy <deployment名> -n <namespace名>
蓝绿部署
思路:假设原来的部署是green,新部署一套blue的。测试完毕后,通过修改labelSelector,将流量切换到blue部署,就起到蓝绿部署的效果了。
配置green版本
web-bluegreen.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-bluegreen
namespace: dev
spec:
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
selector:
matchLabels:
app: web-bluegreen
replicas: 2
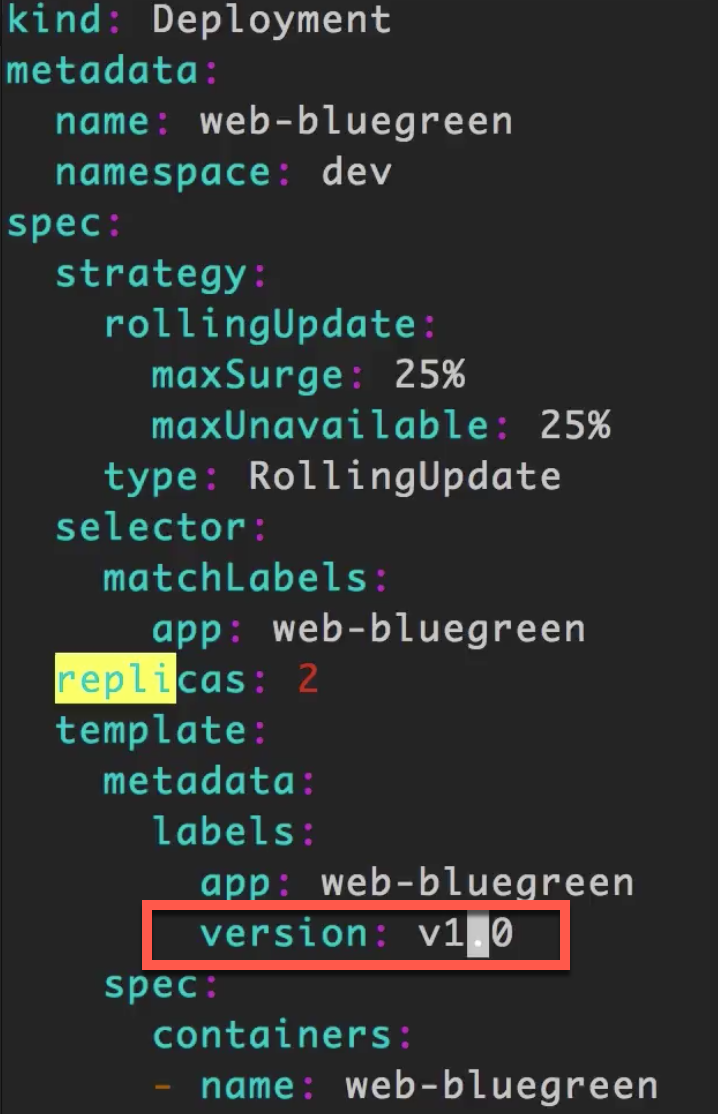
template:
metadata:
labels:
app: web-bluegreen
version: v1.0
spec:
containers:
- name: web-bluegreen
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
resources:
requests:
memory: 1024Mi
cpu: 500m
limits:
memory: 2048Mi
cpu: 2000m
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 3
successThreshold: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /hello?name=test
port: 8080
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 1
successThreshold: 1
timeoutSeconds: 5
注:这里比之前多了一个
version: v1.0的标签。
现在为部署创建service:
bluegreen-service.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
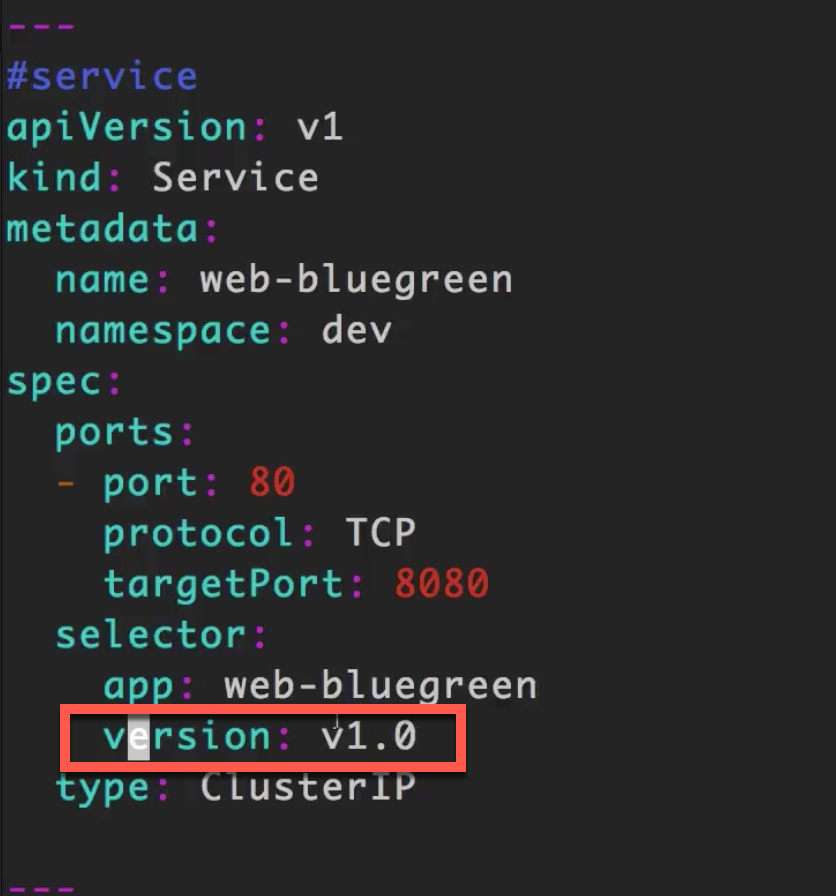
#service
apiVersion: v1
kind: Service
metadata:
name: web-bluegreen
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: web-bluegreen
version: v1.0
type: ClusterIP
#ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web-bluegreen
namespace: dev
spec:
rules:
- host: web-bluegreen.mooc.com
http:
paths:
- path: /
backend:
serviceName: web-bluegreen
servicePort: 80
可以看到,在service中,同样选择带有
version: v1.0的部署。
配置blue版本
修改web-bluegreen.yaml文件,创建一个web-bluegreen-v2的部署,其对应的version: v2.0,假设这个就是我们的blue部署。
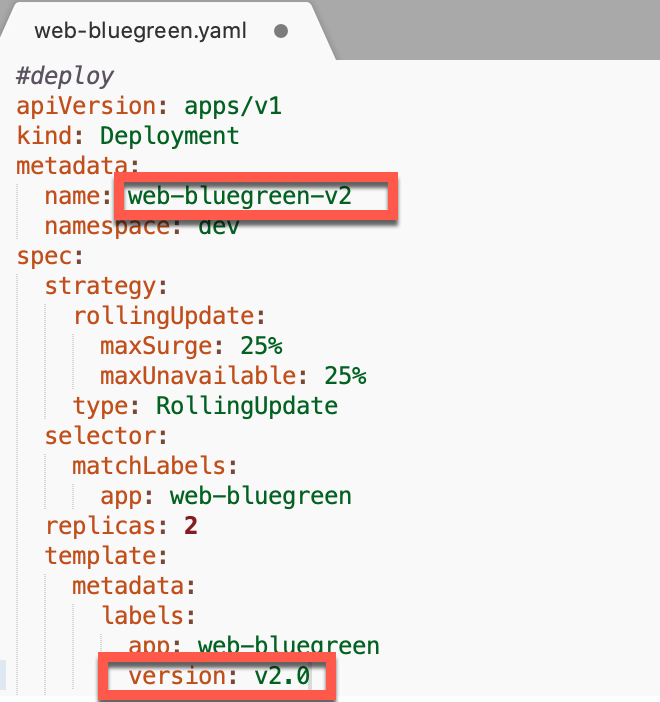
同样部署到k8s上。1
kubectl apply -f web-bluegreen.yaml
查看pod情况:1
kubectl get pods -n dev

可以看到,原来的green部署(web-bluegreen)跟新的blue部署(web-bluegreen-v2)都正常调度起来了。
修改bluegreen-service.yaml文件,将流量切换到带有标签version: v2.0的部署上。

重新部署service后,服务无滚动切换,流量立刻切换到新版本了。
金丝雀部署
修改bluegreen-service.yaml文件,将version节点去掉,这时再部署,流量会轮流导入到1.0和2.0的部署上,进而实现金丝雀部署的效果。