Kubernetes学习笔记(5):Namespace, Resources和Label

Namespace
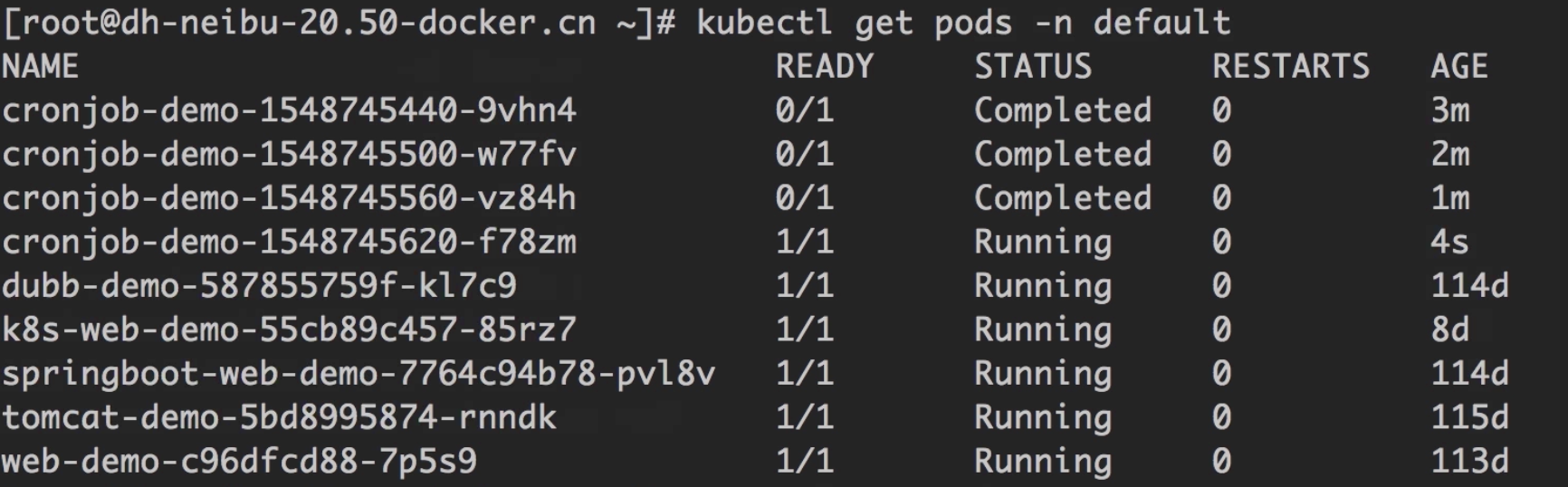
查看某一个Namespace下的pod
默认情况下,所有的pod都是运行在default这个namespace下的。1
kubectl get pods -n default
创建一个Namespace
namespace-dev.yaml1
2
3
4apiVersion: v1
kind: Namespace
metadata:
name: dev
在Namespace下创建资源
web-dev.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
#service
apiVersion: v1
kind: Service
metadata:
name: web-demo
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: web-demo
type: ClusterIP
#ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web-demo
namespace: dev
spec:
rules:
- host: web-dev.mooc.com
http:
paths:
- path: /
backend:
serviceName: web-demo
servicePort: 80

1
kubectl get all -n dev
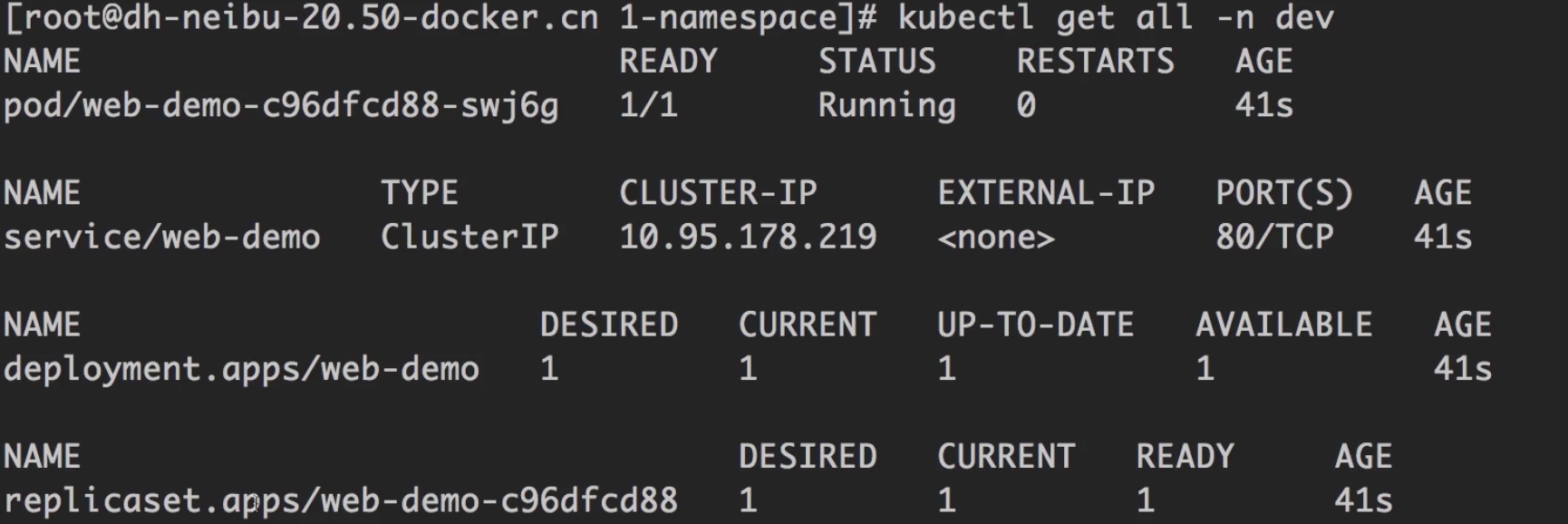
Namespace的隔离性
同一个Namespace下的资源访问
随便找一个pod,进入到其容器中。
比如要测试同一个namespace下的另一个pod上的服务是否可以解析,可以执行ping命令。

用curl, wget也可以验证。
不同Namespace下的资源访问
进入到dev这个namespace下(必须制定-n参数,否则访问的还是default namespace)
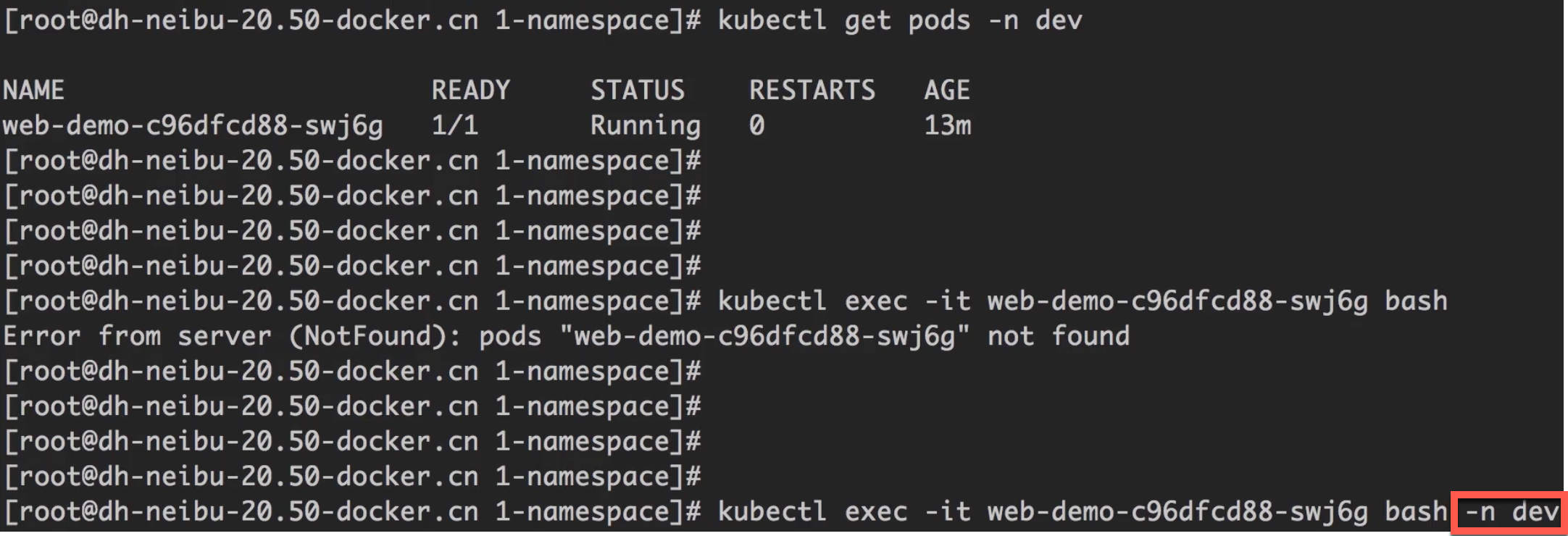
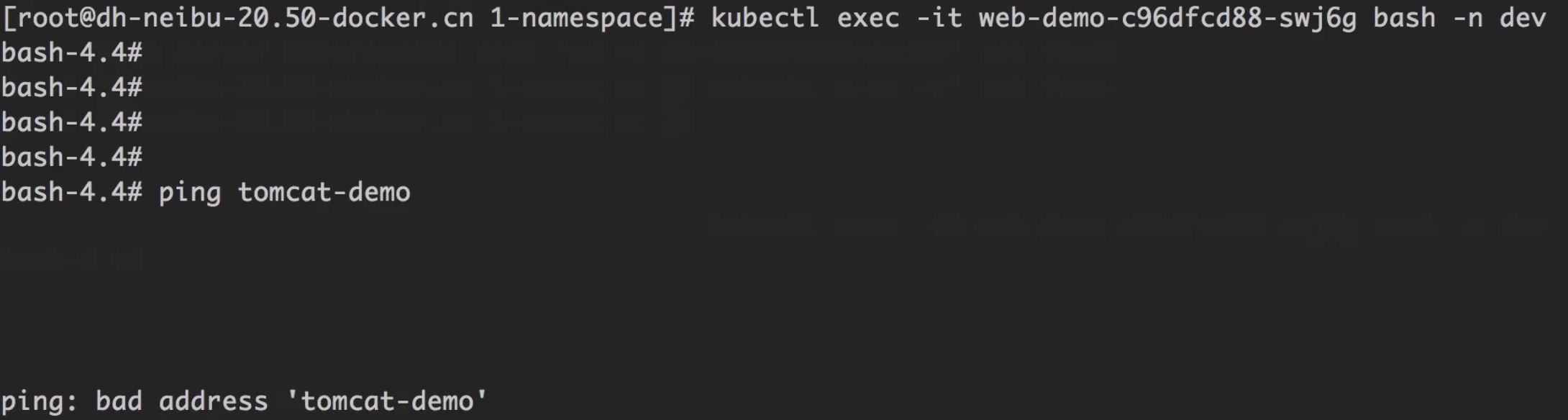
通过DNS无法访问
通过ping访问服务,可以看到无法访问,说明通过DNS层是隔离的。
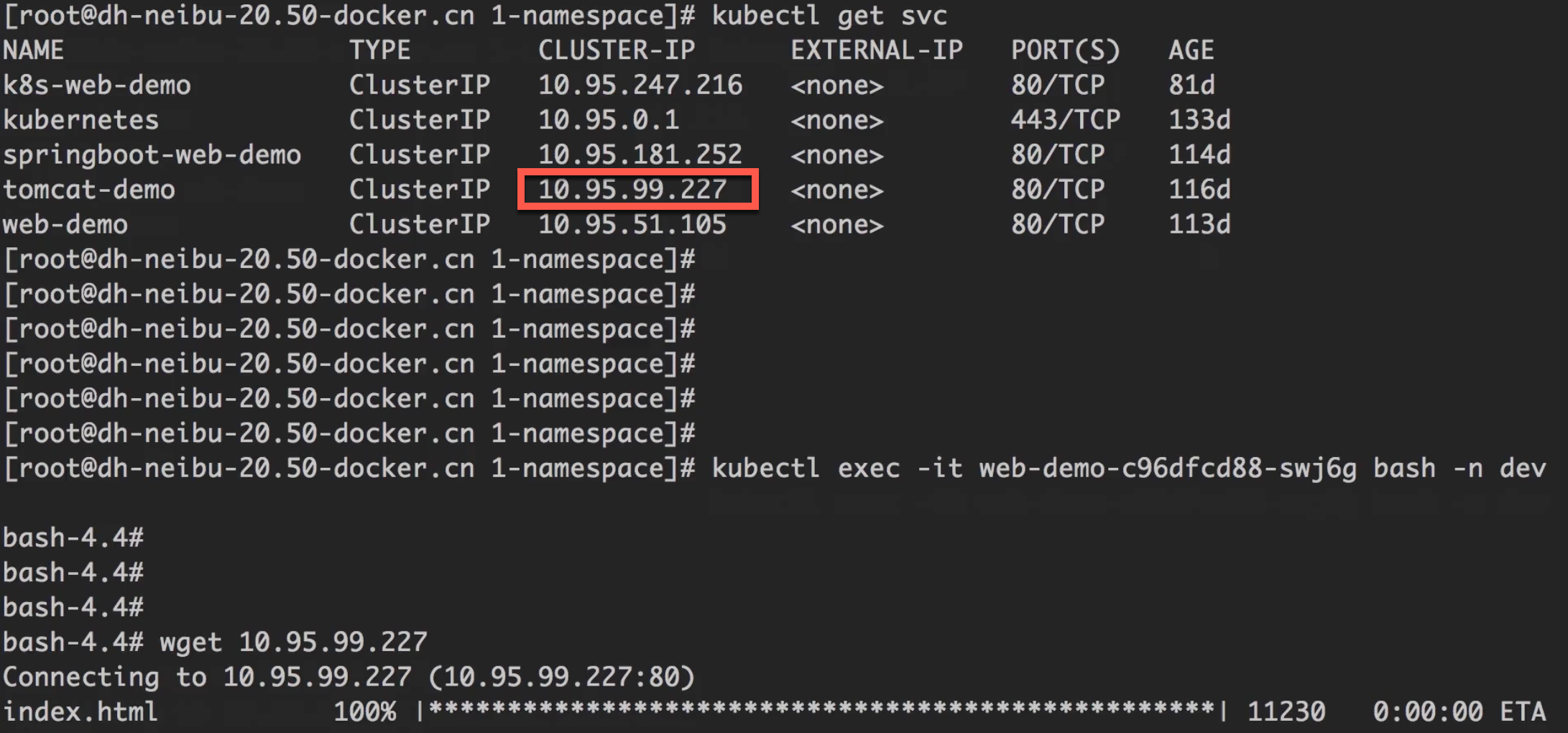
通过服务IP可以访问
尝试通过服务IP访问另一个namespace下的服务,事实上是可以访问到的。
通过pod + port可以访问
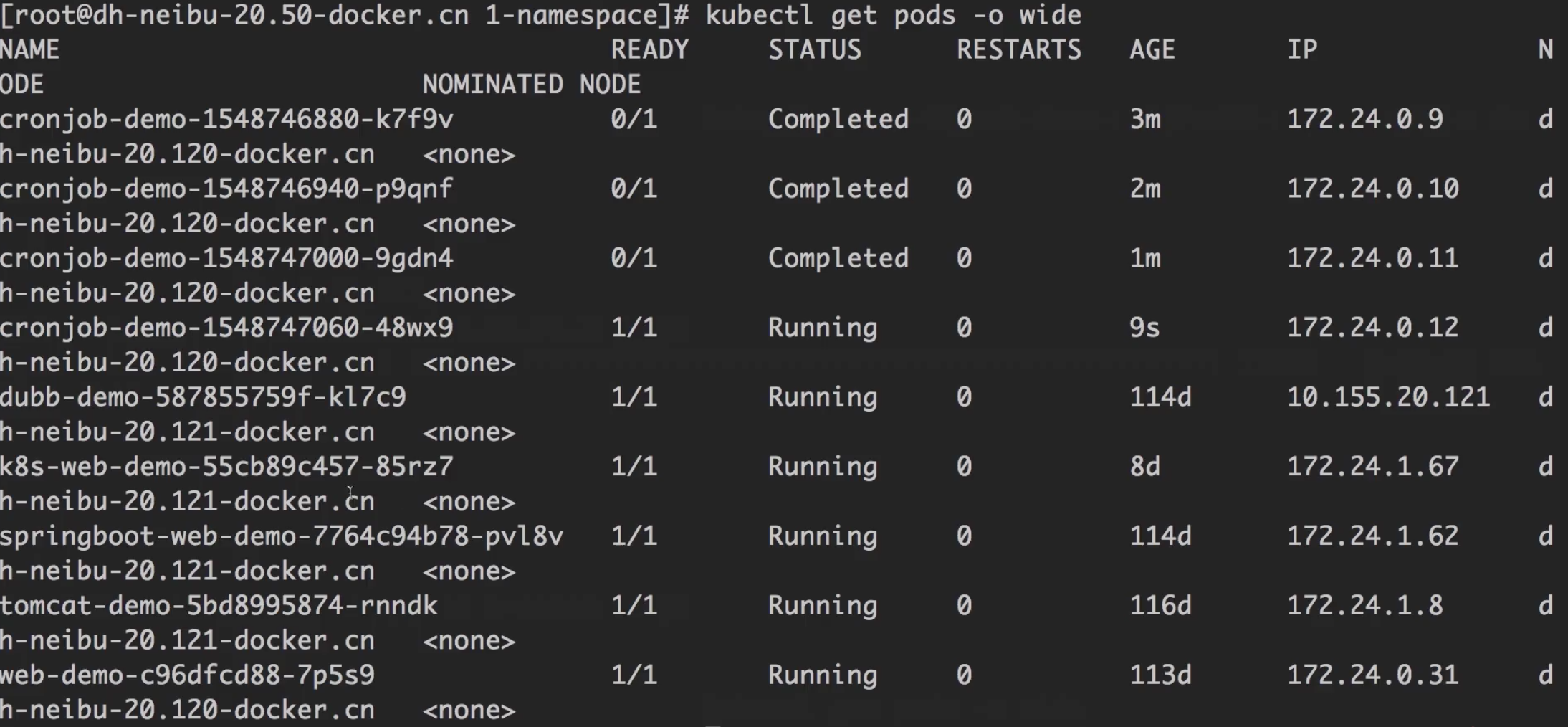
可以看到,通过pod + 端口的方式也是可以访问的。

由此可知,k8s的隔离是DNS解析的隔离,通过服务IP或pod + 端口的方式仍然可以互访。
对上下文限定Namespace
可以通过设置上下文,实现对namespace的限定。
创建kubeconfig
比如:创建一个名叫ctx-dev的上下文,namespace限定为dev。1
2
3
4
5kubectl config set-context ctx-dev \
--cluster=kubernetes \
--user=admin \
--namespace=dev \
--kubconfig=/root/.kube/config
设置默认上下文
1 | kubectl config use-context ctx-dev --kubeconfig=/root/.kube/config |
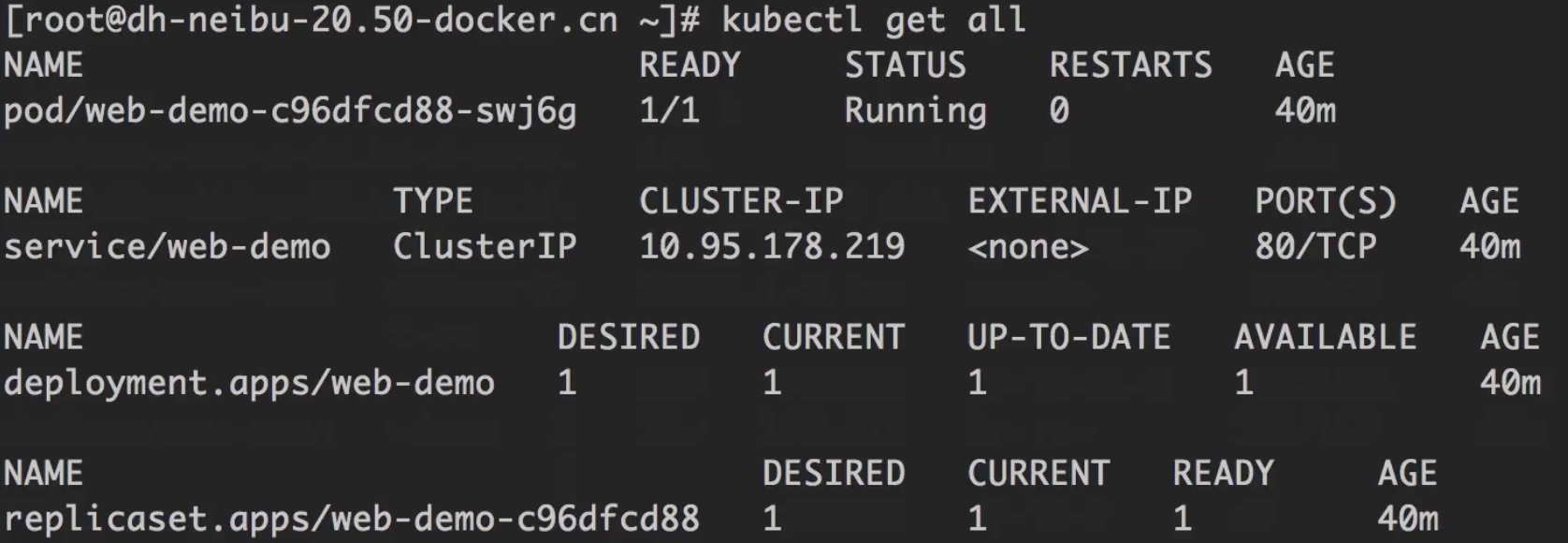
此时运行kubectl get all, 也只能看到dev namespace下的所有资源。
Resources
Resources 主要包括:CPU, 内存, GPU, 持久化存储等。
查看k8s节点资源
1 | kubectl get nodes |
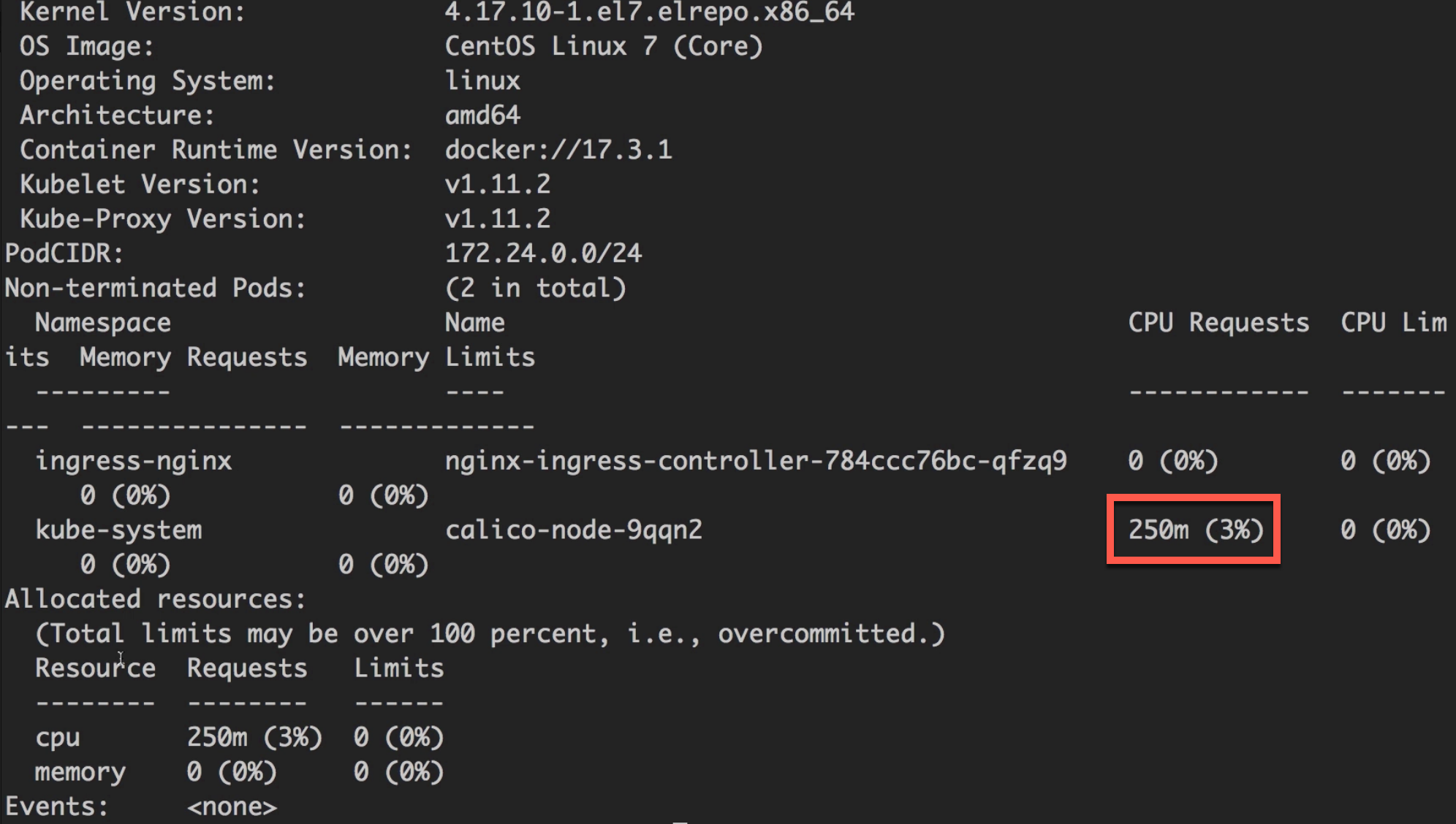
对k8s服务进行资源限制
- memory: 100Mi //限制100MB内存
- cpu: 100m //限制只能使用0.1核CPU
这里有两个地方都有CPU和内存的设置。requests设置的是必须的最小要求,如果超出硬件最大配置,则容器启动时会一直卡在
Pending状态。
而limits限制的是最大的内存,即使设置成超出硬件配置,启动时还是可以起来。
可以通过以下命令查看pod详细失败原因。1
kubectl describe pod <pod名称>
部署到k8s1
kubectl apply -f web-dev.yaml
每次部署后,如果查看节点的状态,可以看到k8s会新启动一个服务,然后把旧服务停掉,因为k8s的资源隔离本质上是利用的docker的资源隔离机制。1
kubectl get pods -n dev

可以切换到容器运行的那台节点上,看看对应的docker容器的情况。1
docker ps | grep web-demo

查看该容器详细信息1
docker inspect <容器id>
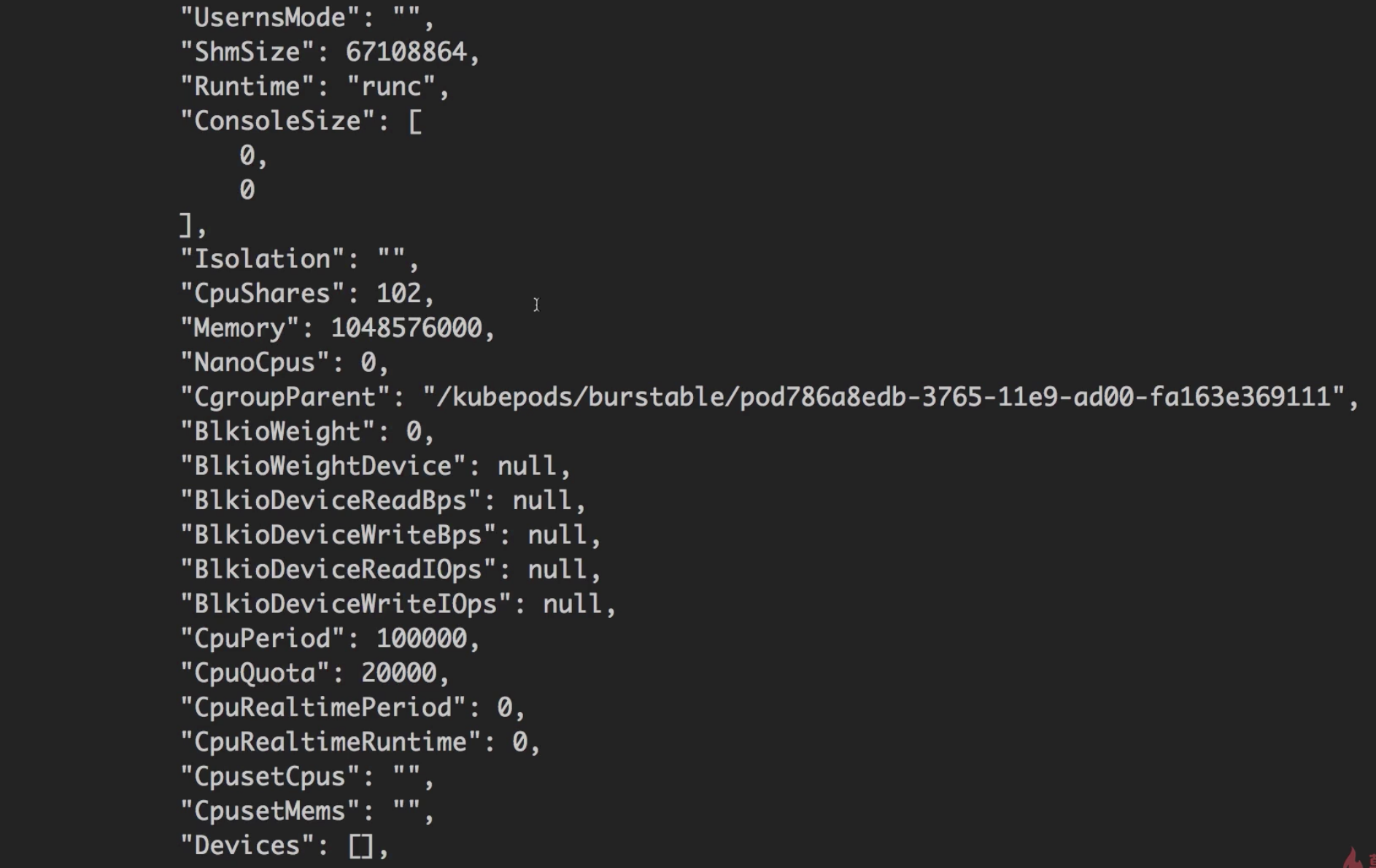
参数解读:
CpuShares: 之前在yaml文件里配置的值是100m,docker会将该值转化为0.1核,之后再乘以1024,就得到这里的102了。这个值在docker里代表相对权重,但发生资源不足时,docker会尝试根据这个权重分配资源。Memory: 这个值就是我们在yaml文件中指定的内存。CpuQuota: yaml文件里设置的最大CPU核数。CpuPeriod: docker默认值,默认值是100000ns。
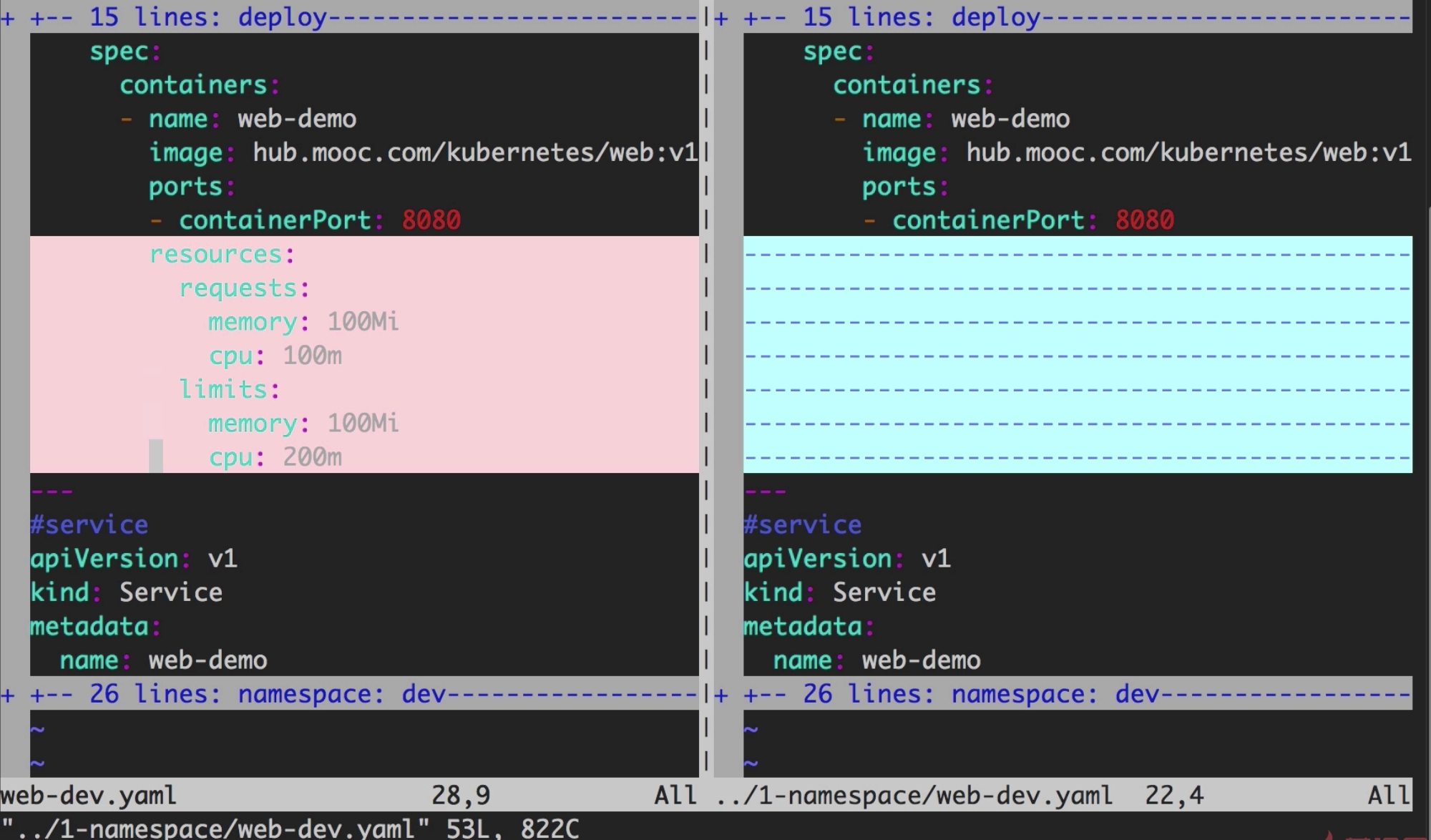
修改yaml文件,测试k8s调度策略
将requests.memory和limits.memory都设置成100Mi。
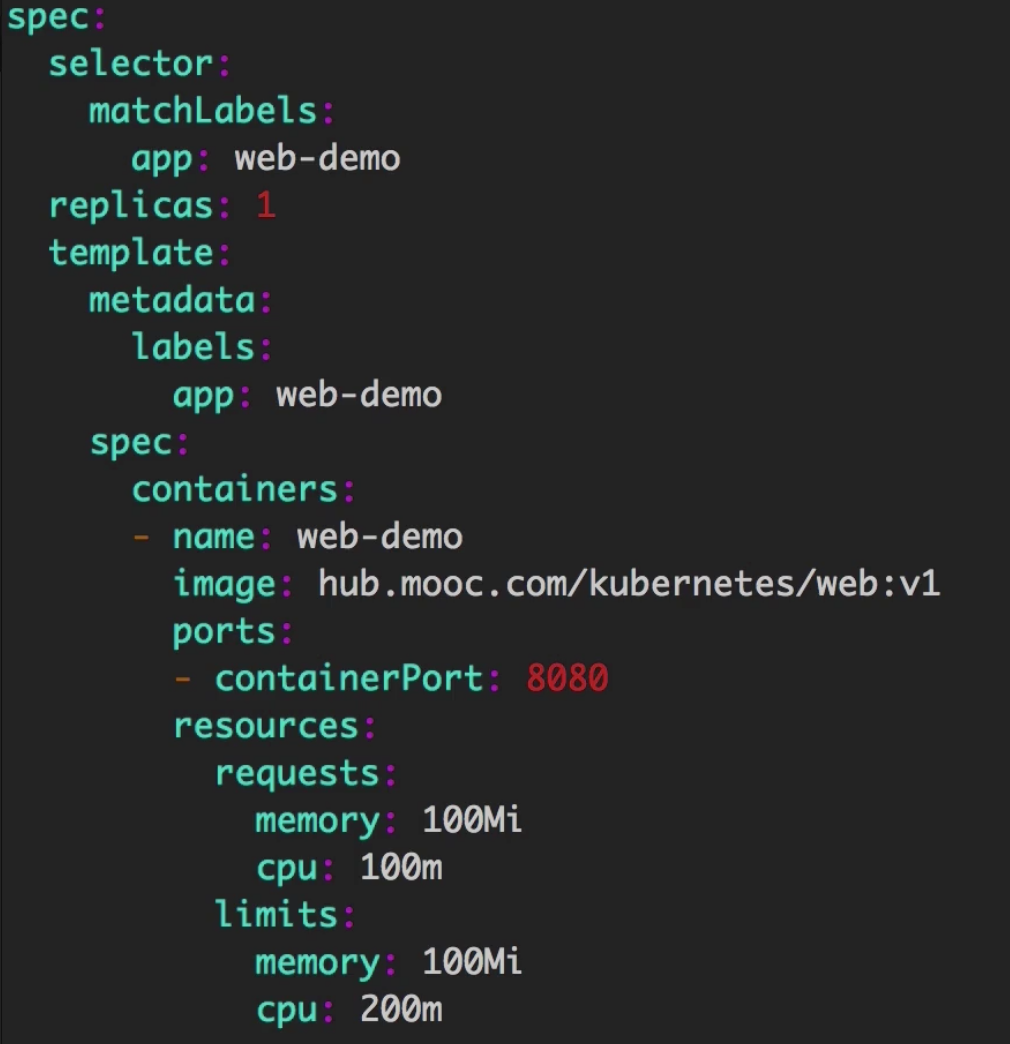
如果docker实例里使用的内存超过了限定内存最大值,则k8s会自动将“有问题的进程”杀掉,但不会终止docker容器。
如果是CPU超过限定,则会限定在最大值,因为CPU是可压缩资源,而内存不是。
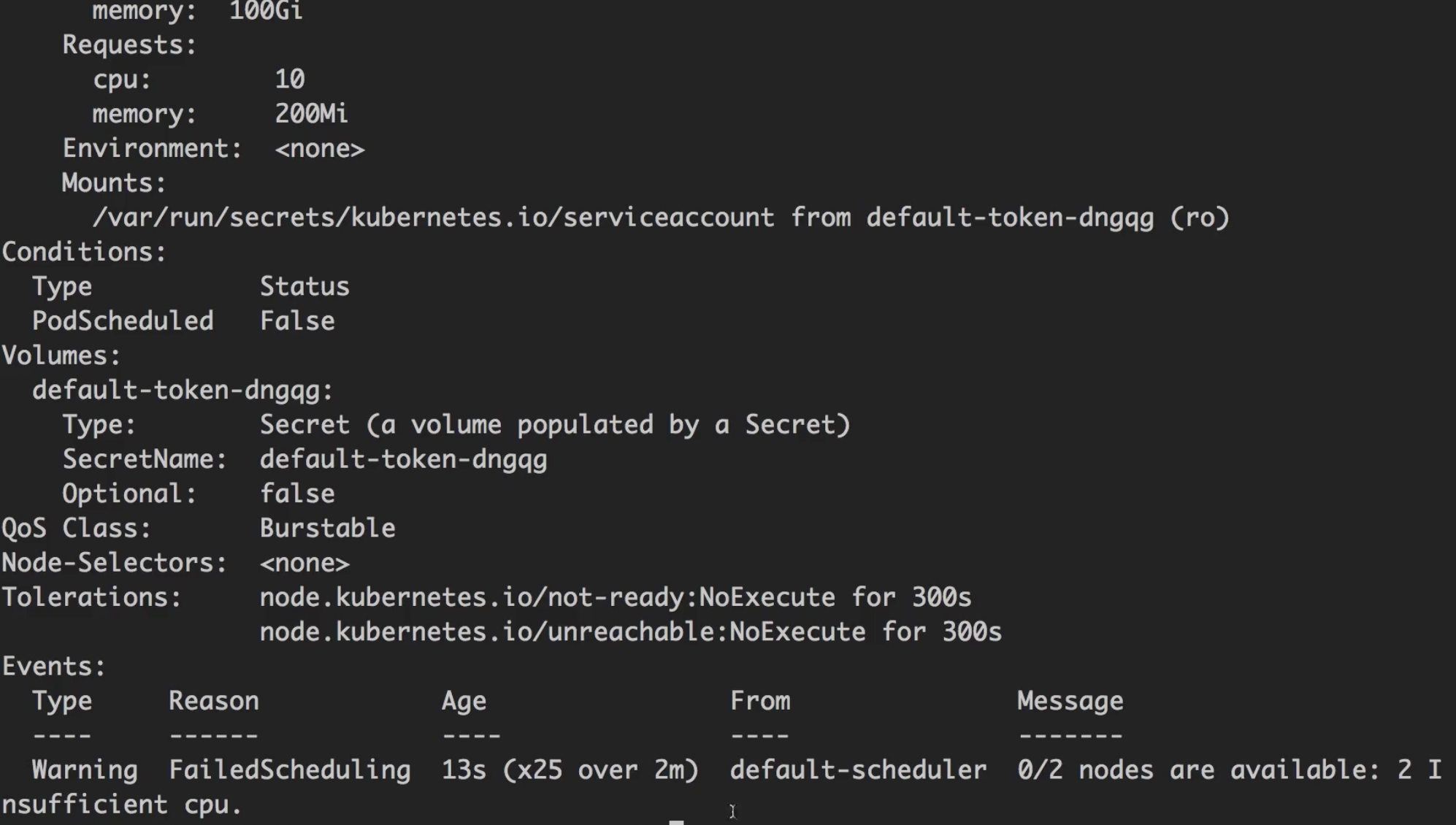
如果将实例数(replicas)改成3, 每个内存改成10GB(服务器硬件一共24GB内存)。
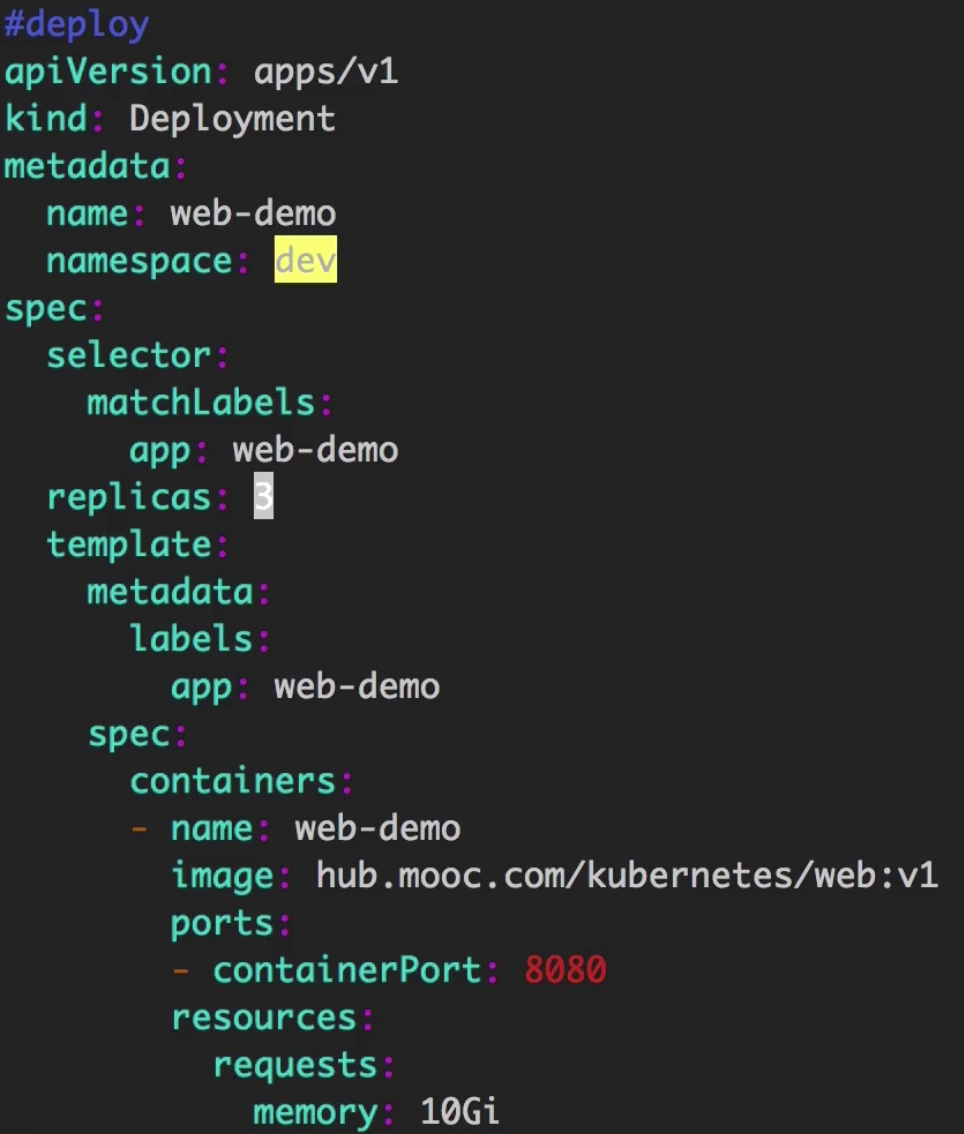
部署服务后可以看到,k8s只允许两个实例启动,第三个一直处于Pending状态。
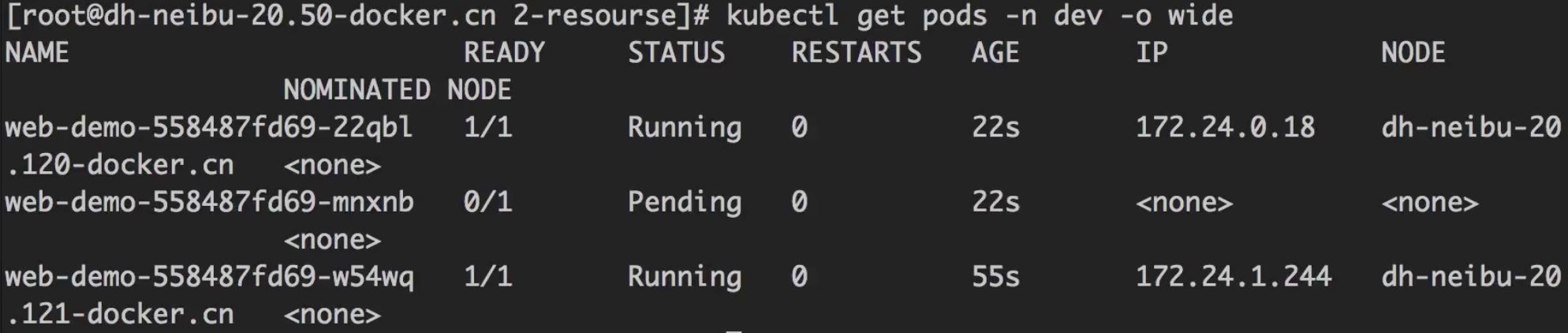
实验说明,
requests要求的配置是要“预留”的,即使实际上还没用到。
测试结论(最佳实践)
设置yaml配置时,
- 如果
requests==limits:此时是最可靠的,推荐使用; - 如果不设置:最不可靠,不推荐;
- 如果
requests>limits:超过时,k8s会根据优先级来分配资源;
使用LimitRange限制资源请求
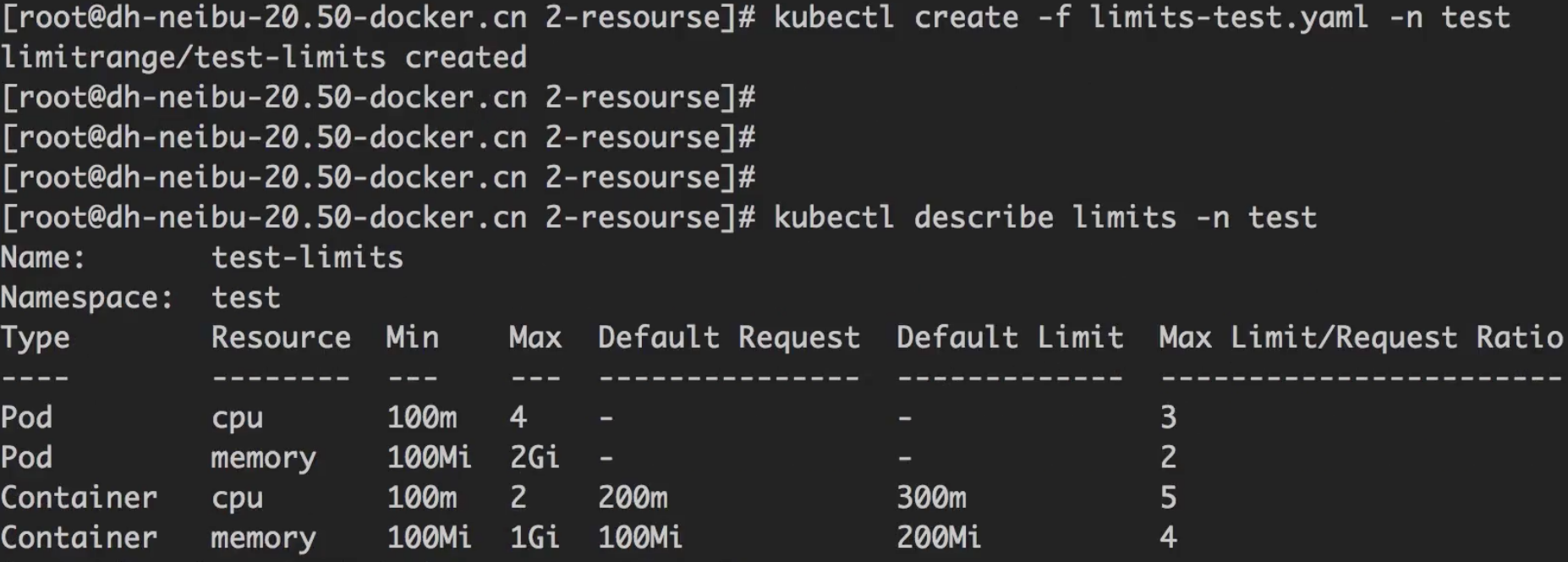
limits-test.yaml对 pod 和 container 分别限定了资源。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32apiVersion: v1
kind: LimitRange
metadata:
name: test-limits
spec:
limits:
- max:
cpu: 4000m
memory: 2Gi
min:
cpu: 100m
memory: 100Mi
maxLimitRequestRatio:
cpu: 3
memory: 2
type: Pod
- default:
cpu: 300m
memory: 200Mi
defaultRequest:
cpu: 200m
memory: 100Mi
max:
cpu: 2000m
memory: 1Gi
min:
cpu: 100m
memory: 100Mi
maxLimitRequestRatio:
cpu: 5
memory: 4
type: Container
新建一个命名空间,将limits-test.yaml部署到k8s新的namespace下,观察其资源占用情况。1
2
3
4
5
6
7
8# 新建一个test命名空间
kubectl create ns test
# 将将`limits-test.yaml`部署到test 命名空间下
kubectl create -f limits-test.yaml -n test
# 查看test命名空间资源占用
kubectl describe limits -n test
在test命名空间下部署一个新的deployment (web-test.yaml),不限制资源。
web-test.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: test
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
可以通过以下命令查看deploy的详细信息;1
kubectl get deploy -n test -o yaml
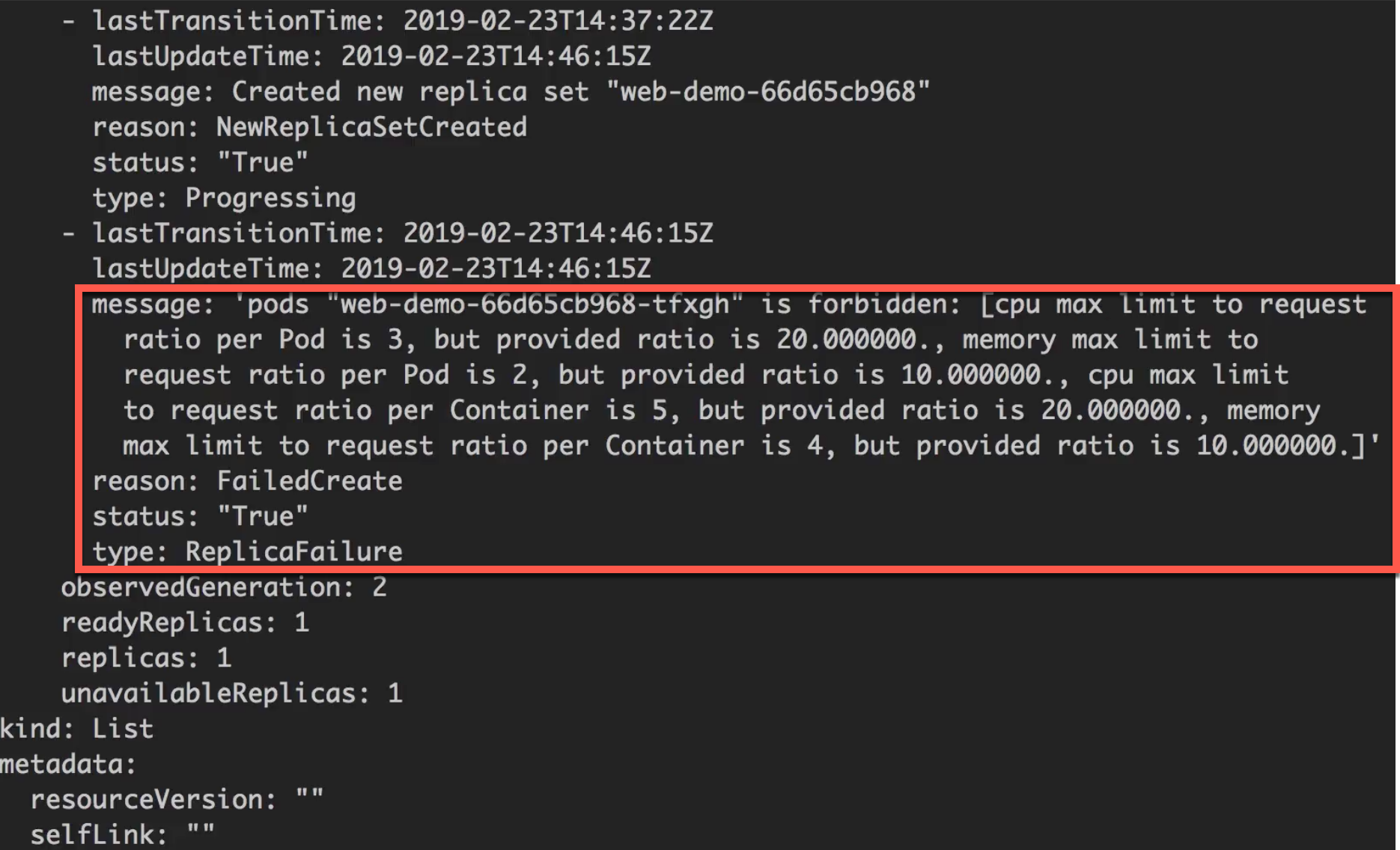
多个团队间的资源配额限制
compute-resource.yaml: 对CPU和内存的限制。1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: ResourceQuota
metadata:
name: resource-quota
spec:
hard:
pods: 4
requests.cpu: 2000m
requests.memory: 4Gi
limits.cpu: 4000m
limits.memory: 8Gi
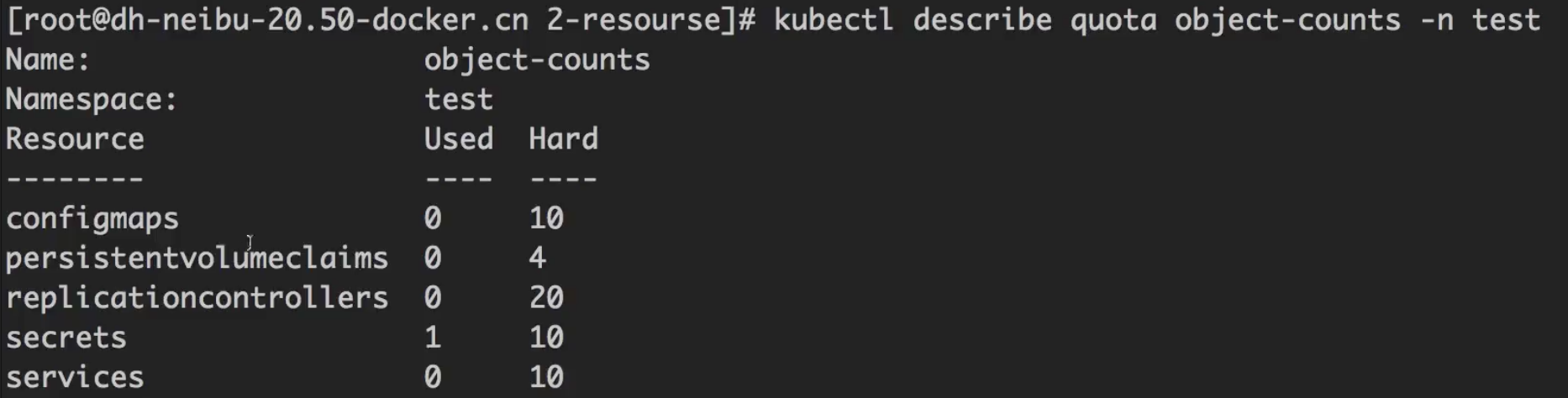
object-count.yaml: 更多资源限制。1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
configmaps: 10
persistentvolumeclaims: 4
replicationcontrollers: 20
secrets: 10
services: 101
2
3
4
5# 对test命名空间限制资源配额
kubectl apply -f object-count.yaml -n test
# 检查资源配额
kubectl describe quota object-counts -n test
Pod驱逐策略 - Evition
soft策略
--eviction-soft=memory.available<1.5Gi --eviction-soft-grace-period=memory.available=1m30s
soft策略配合使用,效果:当内存持续1分30秒小于1.5G时,执行驱逐。
hard策略
--eviction-hard=memory.available<100Mi,nodefs.avaiblable<1Gi,nodefs.inodesFree<5%
hard策略:当满足任意一个条件时,立刻执行;
磁盘紧缺
- 删掉死掉的pod、容器;
- 删除没用的镜像;
- 按优先级、资源占用情况驱逐pod;
内存紧缺
- 驱逐不可靠的pod;
- 驱逐基本可靠的pod(实际使用内存超过正常的);
- 驱逐可靠的pod;
Label
key-value值对,可以“贴”到任何资源上。
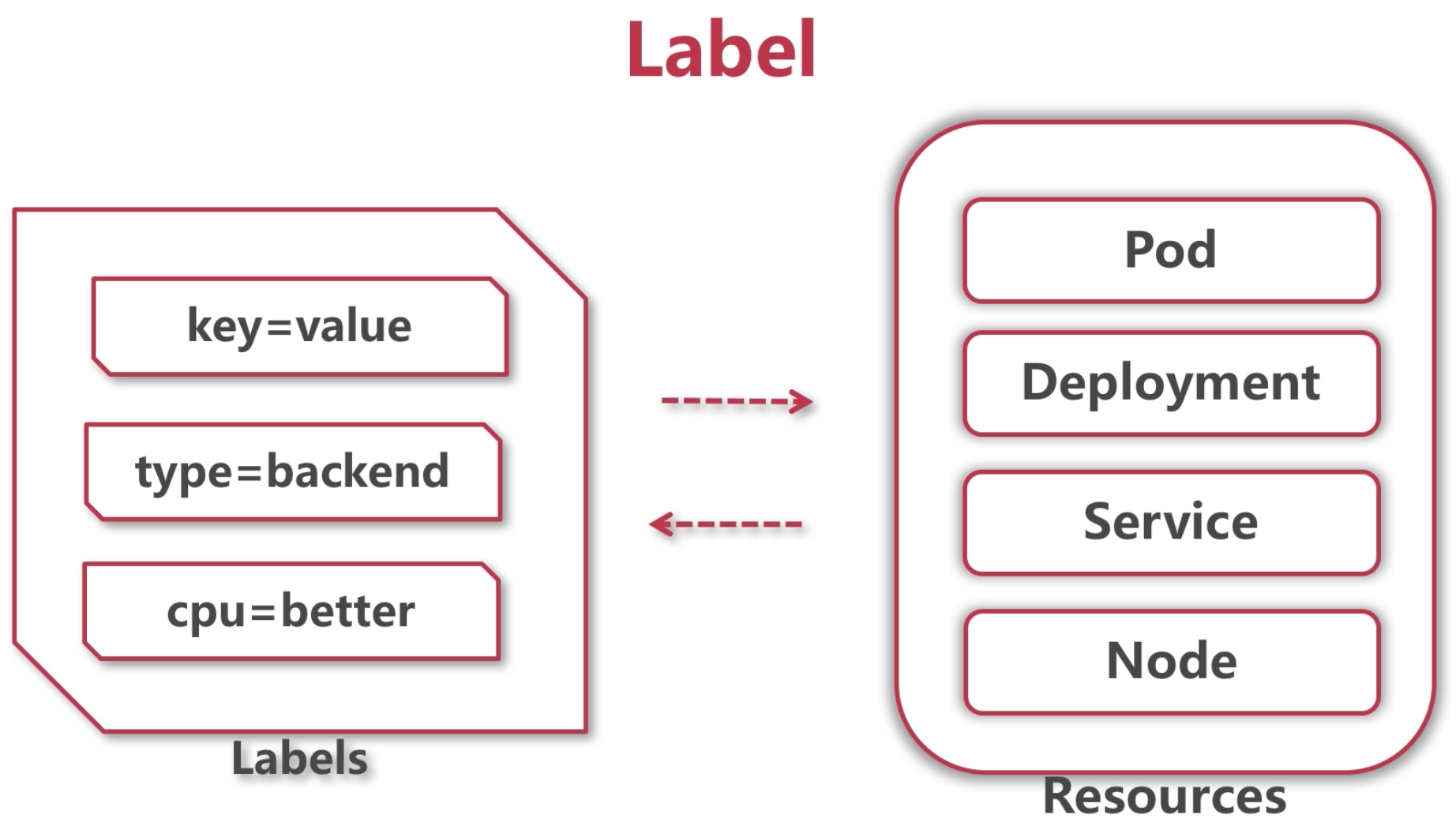
web-dev.yaml: 在metadata里定义了label,之后就可以用selector/matchLabels选择标签了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
#service
apiVersion: v1
kind: Service
metadata:
name: web-demo
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: web-demo
type: ClusterIP
#ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web-demo
namespace: dev
spec:
rules:
- host: web-dev.mooc.com
http:
paths:
- path: /
backend:
serviceName: web-demo
servicePort: 80
不同的deployment的同名label是不冲突的,因为分属不同的实例。
根据label过滤资源
1 | kubectl get pods -l app=web-demo,group=dev -n dev |
在node上指定label
比如,实现在node上打个标签1
kubectl label node <节点名> disktype=ssd
在yaml文件里指定node label,disktype:ssd
