IT知识点整理

虚拟化
服务器虚拟化
x86 CPU架构

Ring3 用户态 (User Mode)
Ring3 用户态 (User Mode):运行在用户态的程序代码需要受到CPU的检查,用户态程序代码只能访问内存页表项中规定能被用户态程序代码访问的页面虚拟地址(受限的内存访问),而且还只能访问 TSS中的I/O Permission Bitmap 中规定能被用户态程序代码访问的端口。甚至不能直接访问外围硬件设备、不能抢占CPU。所有的应用程序(Application)都运行在用户态上。——当运行在用户态的Application需要调用只能被核心态代码直接访问的硬件设备时,CPU会通过特别的接口去调用核心态的代码,以此来实现Application对硬件设备的调用。如果用户态的Application直接调用硬件设备时,就会被Host OS捕捉到并触发异常。
Ring0 核心态 (Kernel Mode)
Ring0 核心态 (Kernel Mode):是HostOS Kernel运行的模式。运行在核心态的代码可以无限制的对系统内存、设备驱动程序、网卡接口、显卡接口等外围硬件设备进行访问。只有 HostOS 能够无限制的访问磁盘、键盘等外围硬件设备的数据,但是首先需要在 HostOS 上安装驱动程序。
CPU虚拟化技术:
- Intel VT-X
- AMD-V
全虚拟化
不需要对GuestOS操作系统软件的源代码做任何的修改,就可以运行在VMM中。
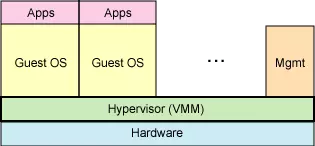
在全虚拟化的虚拟平台中,GuestOS 并不知道自己是一台虚拟机,它会认为自己就是运行在计算机物理硬件设备上的 HostOS。因为全虚拟化的 VMM 会将一个OS所能够操作的CPU、内存、外设等物理设备逻辑抽象成为虚拟CPU、虚拟内存、虚拟外设等虚拟设备后,再交由 GuestOS 来操作使用。这样的 GuestOS 会将底层硬件平台视为自己所有的,但是实际上,这些都是VMM为 GuestOS 制造了这种假象。
优点: GuestOS没有经过任何修改;缺点: 需要底层硬件支持,比如: PowerPC;
典型代表:
- VMware Workstation
- Oracle Virtualbox
- Parallels Desktop
- Microsoft Hyper-V
- KVM
- XEN (HVM)
软件辅助的全虚拟化
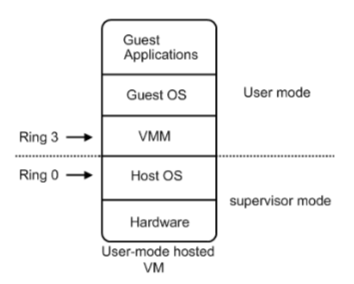
在Intel等CPU厂商还没有发布 x86 CPU虚拟化技术之前,完全虚拟化都是通过软件辅助的方式来实现的。软件辅助的全虚拟化主要是应用了两种机制:
- 特权解除:从上述的软件辅助全虚拟化架构图中可以看出,VMM、GuestOS、Guest Applications 都是运行在 Ring 1-3 用户态。当在 GuestOS 中执行系统内核的特权指令时,一般都会触发异常。这是因为用户态代码不能直接运行在核心态中,而且系统内核的特权指令大多都只能运行在 Ring 0 核心态中。在触发了异常之后,这些异常就会被 VMM 捕获,再由 VMM 将这些特权指令进行虚拟化成为只针对虚拟CPU起作用的虚拟特权指令。其本质就是使用若干能运行在用户态中的非特权指令来模拟出只针对GuestOS有效的虚拟特权指令,从而将特权指令的特权解除掉。
缺点:特权解除的问题在于当初设计标准x86架构CPU时,并没有考虑到要支持虚拟化技术,所以会存在一部分特权指令运行在 Ring 1 用户态上 (19个特权指令),而这些运行在 Ring 1 上的特权指令并不会触发异常然后再被VMM捕获,从而导致在GuestOS中执行的特权指令直接对HostOS造成了影响(GuestOS 和 HostOS 没能做到完全隔离)。针对这个问题,再引入了陷入模拟的机制。
- 陷入模拟:就是 VMM 会对 GuestOS 中的二进制代码 (运行在CPU中的代码) 进行扫描,一旦发现 GuestOS 执行的二进制代码中包含有运行在用户态上的特权指令二进制代码时,就会将这些二进制代码翻译成虚拟特权指令二进制代码或运行在核心态中的特权指令二进制代码,从而强制触发异常。这样就能够很好的解决了运行在 Ring 1 用户态上的特权指令没有被VMM捕获的问题,更好的实现了 GuestOS 和 HostOS 的隔离。
后来CPU厂商们发布了能够判断特权指令归属的标准x86 CPU之后,迎来了硬件辅助全虚拟化。
QEMU
QEMU 是一个独立的虚拟化解决方案,通过 Intel-VT 或 AMD SVM 实现全虚拟化,安装qemu的系统,可以直接模拟出另一个完全不同的系统环境,虚拟机的创建通过 qemu-image 既可完成。QEMU 本身可以不依赖于KVM,但是如果有KVM的存在并且硬件(处理器)支持比如 Intel-VT 功能,那么QEMU在对处理器虚拟化这一块可以利用KVM提供的功能来提升性能。
VMware Workstation
Oracle Virtualbox
Parallels Desktop
硬件辅助的全虚拟化
硬件辅助全虚拟化主要使用了支持虚拟化功能的CPU进行支撑,CPU可以明确的分辨出来自GuestOS的特权指令,并针对GuestOS进行特权操作,而不会影响到HostOS。
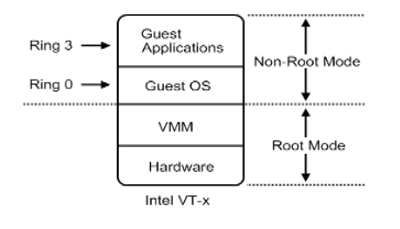
从更深入的层次来说,虚拟化CPU形成了新的CPU执行状态: Non-Root Mode 和 Root Mode 。GuestOS运行在Non-Root Mode 的 Ring 0 核心态中,这表明 GuestOS 能够直接执行特权指令而不再需要特权解除和陷入模拟机制。并且在硬件层上面紧接的就是虚拟化层的VMM,而不需要HostOS。这是因为在硬件辅助全虚拟化的VMM会以一种更具协作性的方式来实现虚拟化 —— 将虚拟化模块加载到HostOS的内核中。
例如:KVM,KVM通过在HostOS内核中加载 KVM Kernel Module 来将 HostOS 转换成为一个VMM。所以此时VMM可以看作是HostOS,反之亦然。这种虚拟化方式创建的 GuestOS 知道自己是正在虚拟化模式中运行的 GuestOS,KVM就是这样的一种虚拟化实现解决方案。1
2
3
4## 判断CPU是否支持硬件虚拟化
grep -i -E '(vmx|svm|lm)' /proc/cpuinfo
vmx:Intel VT-x
svm:AMD AMD-v
KVM

KVM 是集成到 Linux 内核的 Hypervisor,是x86架构且硬件支持虚拟化技术(Intel-VT 或AMD-V)的 Linux 全虚拟化解决方案。准确来说,KVM是 Linux kernel 的一个模块,可以用来创建虚拟机。但仅有KVM模块是远远不够的,因为用户无法直接控制内核模块去做事,还必须有一个运行在用户空间的工具才行。这个用户空间的工具,KVM开发者选择了已经成型的开源虚拟化软件QEMU。
QEMU也是一个虚拟化软件,它可以虚拟不同的CPU。比如:在x86的CPU上虚拟一个Power的CPU,并可利用它编译出可运行在Power上的程序。KVM使用了QEMU的一部分,并稍加改造,就成了可控制KVM的用户空间工具。
KVM只支持x86平台,且依赖于HVM(Intel-VT, AMD-V)。

KVM的核心组件
libvirt:操作和管理KVM虚机的虚拟化 API,使用C语言编写,可以由Python, Ruby, Perl, PHP, Java 等语言调用。可以操作包括KVM,VMware,XEN,Hyper-v, LXC等 Hypervisor;Virsh:基于libvirt的命令行工具(CLI);Virt-Manager:基于libvirt的GUI工具;virt-v2v:虚机格式迁移工具;virt-*工具:包括Virt-install(创建KVM虚机的命令行工具),Virt-viewer(连接到虚机屏幕的工具),Virt-clone(虚机克隆工具),virt-top等;sVirt:安全工具;
VMware ESXi
支持Windows、Linux等操作系统。
Microsoft Hyper-V
支持Windows、Linux等操作系统。
Xen (HVM)
支持Windows、Linux等操作系统。
半虚拟化 (准虚拟化)
需要对GuestOS的内核代码做一定的修改(在GuestOS的源代码级别上修改特权指令来回避上述的虚拟化漏洞),才能将GuestOS运行在半虚拟化的VMM中。
半虚拟化除了修改内核外还有另外一种实现方法 —— 在每一个GuestOS中安装半虚拟化软件,e.g. VMTools、RHEVTools

优点: 性能优越,几乎与原始系统相近;缺点: 需要对操作系统进行一定的修改,GuestOS的镜像文件并不通用,更新慢;
Xen
Xen是一款虚拟化软件,支持半虚拟化和完全虚拟化。它在不支持VT技术的cpu上也能使用,但是只能以半虚拟化模式运行。半虚拟化模式下,仅支持Linux操作系统。
- virt-manager(GUI): 用于管理和安装系统;
- virt-install: 只用于安装系统;
服务器虚拟化总结
| 软件辅助全虚拟化 | 硬件辅助全虚拟化 | 操作系统协助/半虚拟化 | |
|---|---|---|---|
| 实现技术 | BT和直接执行 | 遇到特权指令转到root模式执行 | Hypercall |
| 客户操作系统修改 | 无需修改客户操作系统 | 无需修改客户操作系统 | 客户操作系统需要修改来支持hypercall,因此它不能运行在物理硬件本身或其他的hypervisor上 |
| 兼容性 | 好 | 好 | 差,半虚拟化模式下,仅支持Linux操作系统 |
| 性能 | 差 | 全虚拟化下,CPU需要在两种模式之间切换,带来性能开销;但是,其性能在逐渐逼近半虚拟化。 | 好。半虚拟化下CPU性能开销几乎为0,虚机的性能接近于物理机。 |
| 应用厂商 | VMware Workstation, QEMU, Virtual PC | VMware ESXi, Microsoft Hyper-V, Xen (HVM), KVM | Xen |
内存虚拟化
软件级内存虚拟化
虚拟内存
硬件硬件级内存虚拟化
Intel EPT (Extended Page Table)
AMD NTP (Nested Page Table)
存储虚拟化
LVM
LVM基本术语
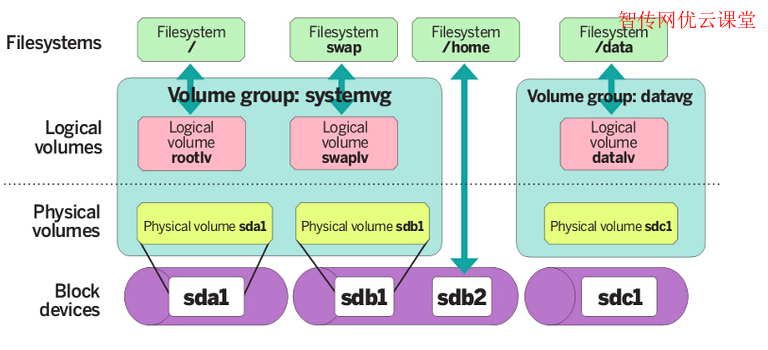
物理存储介质(The Physical Media): 这里是指系统的存储设备, 如:/dev/hda1, /dev/sda等,是存储系统最底层的存储单元。
物理卷(PV, Physical Volume): 物理卷就是指磁盘,磁盘分区或从逻辑上与磁盘分区具有同样功能的设备(如RAID),是LVM的基本存储逻辑块,但和基本的物理存储介质(如分区,磁盘等)比较,却包含有与LVM相关的管理参数。当前LVM允许你在每个物理卷上保存这个物理卷的0-2分元数据拷贝,默认为1,保存在设备的开始处,为2时,保存在设备的结束处。硬盘分区后(还未格式化为文件系统)使用pvcreate命令可以将分区创建为pv,要求分区的system ID为8e,即为LVM格式的系统标识符。
卷组(VG, Volume Group): LVM卷组类似与非LVM系统中的物理硬盘,由其物理卷组成,可以在卷组上创建一个或多个(LVM分区)逻辑卷,LVM卷组由一个或多个物理卷组成。将多个PV组合起来,使用vgcreate命令创建成卷组,这样卷组包含了多个PV就比较大了,相当于重新整合了多个分区后得到的磁盘。虽然VG是整合多个PV的,但是创建VG时会将VG所有的空间根据指定的PE大小划分为多个PE,在LVM模式下的存储都以PE为单元,类似于文件系统的Block。
PE(Physical Extend): PE是VG中的存储单元,实际存储的数据都是存储在这里面的。
LV(Logical Volume): VG相当于整合过的硬盘,那么LV就相当于分区,只不过该分区是通过VG来划分的。VG中有很多PE单元,可以指定将多少个PE划分给一个LV,也可以直接指定大小(如多少兆)来划分。划分为LV之后就相当于划分了分区,只需再对LV进行格式化即可变成普通的文件系统。
RAID 技术
- RAID 0

- RAID 1
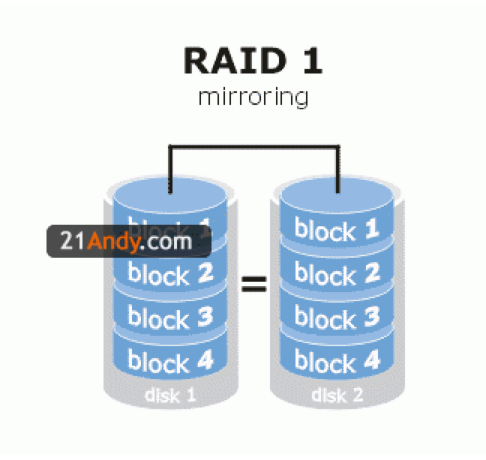
- RAID 5

- RAID 10

网络虚拟化
显卡虚拟化
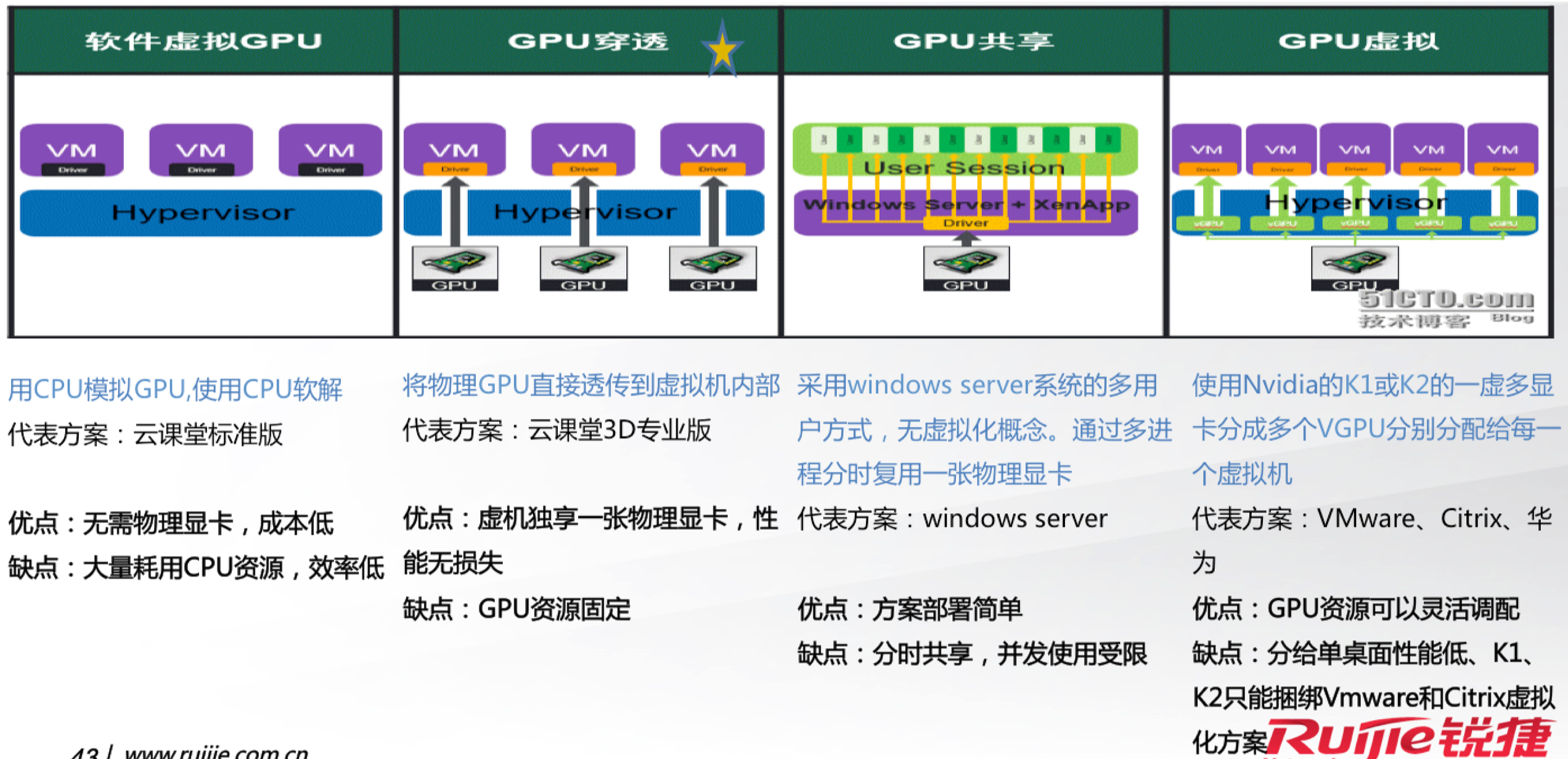
桌面虚拟化

容器虚拟化
LXC
libcontainer
runC
openvz
云管平台
OpenStack
VMware vSphere
分布式系统架构
分布式理论
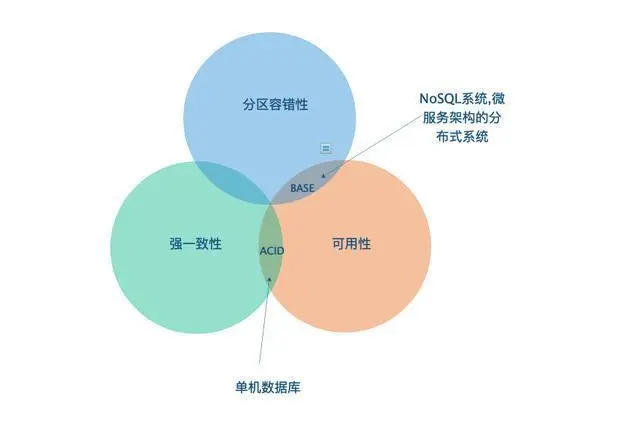
CAP理论
CAP是”Consistency”,”Availabilty”,”Partition Tolerance”的简称,分别代表了: 强一致性,可用性和分区容忍性,它们的含义分别如下:
- 强一致性: 在分布式系统同一份数据有多副本的情况下,对于数据的操作效果和只有单份数据一样。
- 可用性: 客户端在任何时刻对数据的读/写操作都应该保证在时限内完成。
- 分区容忍性: 当分布式系统出现网络分区,不同分区间的机器无法进行网络通信时,系统仍然能够继续工作。
BASE理论
由CAP定理可知,在分布式系统中过于追求数据的强一致性将导致可用性一定程度被牺牲,这意味着系统将不能很好的响应用户的请求,这会一定程度影响用户体验。因而对于大部分布式系统而言,应当在保证系统高可用的前提下去追求数据的一致性,BASE原则正是对这一思想的描述。
BASE理论的核心思想是: 把分布式系统的可用性放在首位,放弃CAP中对数据强一致性的追求,只要系统能保证数据最终一致。
- 基本可用(Basically Available): 系统在绝大部分时间应处于可用状态,允许出现故障损失部分可用性,但保证核心可用。
- 软状态(Soft State): 数据状态不要求在任何时刻都保持一致,允许存在中间状态,而该状态不影响系统可用性。对于多副本的存储系统而言,就是允许副本之间的同步存在延时,并且在这个过程中系统依旧可以响应客户端请求。
- 最终一致性(Eventual Consistency): 尽管软状态不要求分布式数据在任何时刻都保持一致,但经过一定时间后,这些数据最终能达到一致性状态。
CAP, BASE, ACID的关系
幂等性
解决幂等的方法
- 全局唯一ID:根据业务生成一个全局唯一ID,在调用接口时会传入该ID,接口提供方会从相应的存储系统比如Redis中去检索这个全局ID是否存在,如果存在则说明该操作已经执行过了,将拒绝本次服务请求;否则将相应该服务请求并将全局ID存入存储系统中,之后包含相同业务ID参数的请求将被拒绝。
- 去重表:这种方法适用于在业务中有唯一标识的插入场景。比如在支付场景中,一个订单只会支付一次,可以建立一张去重表,将订单ID作为唯一索引。把支付并且写入支付单据到去重表放入一个事务中,这样当出现重复支付时,数据库就会抛出唯一约束异常,操作就会回滚。这样保证了订单只会被支付一次。
- 多版本并发控制:适合对更新请求作幂等性控制,比如要更新商品的名字,这是就可以在更新的接口中增加一个版本号来做幂等性控制
- 状态机控制:适合在有状态机流转的情况下,比如订单的创建和付款,订单的创建肯定是在付款之前。这是可以添加一个int类型的字段来表示订单状态,创建为0,付款成功为100,付款失败为99,则对订单状态的更新就可以这样表示。
- 插入或更新:在MySQL数据库中,如果在insert语句后面带上ON DUPLICATE KEY UPDATE 子句,而要插入的行与表中现有记录的惟一索引或主键中产生重复值,则对旧行进行更新;否则执行新纪录的插入。我们可以利用该特性防止记录的重复插入,比如good_id和category_id构成唯一索引,则重复执行多次该SQL,数据库中也只会有一条记录。
微服务框架选型


RESTful框架
Spring Cloud
Spring Cloud,来源于 Spring Source ,具有 Spring 社区的强大背书外,还有 Netflix 强大的后盾与技术输出。Netflix 作为一家成功实践微服务架构的互联网公司,在几年前就把几乎整个微服务框架栈开源贡献给了社区,这些框架开源的整套微服务架构套件是 Spring Cloud 的核心。
Spring Cloud Config: 配置中心,利用 Git 集中管理程序的配置。Spring Cloud Eureka: 服务中心(类似于管家的概念,需要什么直接从这里取,就可以了),一个基于 REST 的服务,用于定位服务,以实现云端中间层服务发现和故障转移。Spring Cloud Hystrix: 熔断器,容错管理工具,旨在通过熔断机制控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Spring Cloud Zuul: 网关,是在云平台上提供动态路由,监控,弹性,安全等边缘服务的框架。Web 网站后端所有请求的前门。Spring Cloud Ribbon: 负载均衡。Spring Cloud Fegin: REST客户端。Spring Cloud Bus: 消息总线,利用分布式消息将服务和服务实例连接在一起,用于在一个集群中传播状态的变化。Spring Cloud Security安全控制,在 Zuul 代理中为 OAuth2 REST 客户端和认证头转发提供负载均衡。Spring Cloud Sleuth: 分布式链路监控,SpringCloud 应用的分布式追踪系统,和 Zipkin,HTrace,ELK 兼容。Spring Cloud Stream: 消息组件,基于 Redis,Rabbit,Kafka 实现的消息微服务,简单声明模型用以在 Spring Cloud 应用中收发消息。
RPC框架
- 求稳:Dubbo, thrift
- 追新:gRPC
Thrift
gRPC
Dubbo
Dubbo 是一个分布式服务框架,是国内互联网公司开源做的比较不错的阿里开放的微服务化治理框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。其核心部分包含:
- 远程通讯: 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式;
- 集群容错: 提供基于接口方法的透明远程过程调用,包括多协议支持,以及软负载均衡,失败容错,地址路由,动态配置等集群支持;
- 自动发现: 基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。
Dubbox
当当 Dubbox 扩展了 Dubbo 支持 RESTful 接口暴露能力。
新锐框架
Istio
Istio 作为用于微服务服务聚合层管理的新锐项目,是 Google、IBM、Lyft(海外共享出行公司、Uber劲敌) 首个共同联合开源的项目,提供了统一的连接,安全,管理和监控微服务的方案。
目前首个测试版是针对 Kubernetes 环境的,社区宣称在未来几个月内会为虚拟机和 Cloud Foundry 等其他环境增加支持。 Istio 将流量管理添加到微服务中,并为增值功能(如安全性,监控,路由,连接管理和策略)创造了基础。
- HTTP、gRPC 和 TCP 网络流量的自动负载均衡;
- 提供了丰富的路由规则,实现细粒度的网络流量行为控制;
- 流量加密、服务间认证,以及强身份声明;
- 全范围(Fleet-wide)的策略执行;
- 深度遥测和报告。
消息队列MQ
- 轻量级:RabbitMQ
- 重量级:Kafka, RocketMQ
- 没有特殊原因,不要选择ActiveMQ
| Kafka | RocketMQ | RabbitMQ | |
|---|---|---|---|
| 设计定位 | 系统间的数据流管道,实时数据处理。例如:常规消息系统、网站活性跟踪、监控数据、日志收集、处理等 | 非日志的可靠消息传输,例如:交易、订单、充值、流计算、消息推送、流失处理,binglog分发等 | 可靠消息传输,和RocketMQ类似 |
| 成熟度 | 日志领域成熟 | 成熟 | 成熟 |
| 所属 | Apache | Alibaba -> Apache | Mozilla Public License |
| 社区活跃度 | 高 | 中 | 高 |
| API完备性 | 高 | 高 | 高 |
| 文档完备性 | 高 | 高 | 高 |
| 开发语言 | Scala | Java | Erlang |
| 支持协议 | 一套自行设计的基于TCP的二进制协议 | 自己定义的一套协议 | AMQP |
| 客户端语言 | C/C++, Python, Go, Erlang, .NET, Ruby, Node.js, PHP等 | Java | Java, C, C++, Python, PHP, Perl等 |
| 持久化方式 | 磁盘文件 | 磁盘文件 | 内存、文件 |
| 部署方式 | 单机/集群 | 单机/集群 | 单机/集群 |
| 集群管理 | Zookeeper | name server | |
| 选主方式 | 从ISR中自动选举一个leader | 不支持自动选主,通过设定brokername, brockerid实现。brokername相同,brockerid=0时为master,其他为slave | 最早加入集群的broker |
| 可用性 | 非常高,分布式主从 | 非常高,分布式主从 | 高,主从,采用镜像模式实现,数据量大时可能产生性能瓶颈 |
| 主从切换 | 自动切换,N个副本,允许N-1个失败;master失效后自动从ISR中选举一个master | 不支持自动切换。master失效以后,不能向master发送消息,consumer大概30s(默认)可感知此事件,伺候从slave消费。如果master无法恢复,异步复制时可能出现部分信息丢失。 | 自动切换。最早加入集群的slave会成为master |
| 数据可靠性 | 很好。支持producer单挑发送、同步刷盘、同步复制 | 很好。producer单条发送,broker端支持同步刷盘、异步刷盘,同步双写、异步复制 | 好。producer支持同步/异步ack,支持队列数据持久化,镜像模式中支持主动同步。 |
| 消息写入性能 | 非常好。每条10个字节测试:百万条/s | 很好。每条10个字节测试:单机单broker 7万/s,单机 3 broker 12万/s | RAM约为RocketMQ的1/2,Disk性能约为RAM性能的1/3 |
| 性能稳定性 | 队列/分区多时性能不稳定,明显下降。消息堆积时性能稳定。 | 队列较多、消息堆积时性能稳定。 | 消息堆积时,性能不稳定。 |
| 单机支持的队列数 | 单机超过64个队列/分区,Load会发生明显的飘高现象。队列越多,load越高,发送消息响应时间边长 | 单机支持最高5万个队列,Load不会发生明显变化 | 依赖于内存 |
| 堆积能力 | 非常好。消息存储在log中,每个分区一个log文件 | 非常好。所有消息存储在同一个commit log中 | 一般 |
| 复制备份 | 消息先写入leader的log,followers从leader中pull,然后先ack leader,在写入log中。ISR中维护与leader不同的列表,落后太多的follower会被删除。 | 同步双写,异步复制;slave启动线程从master中拉数据 | 普通模式下不复制;镜像模式下,消息先到master,然后写到slave上。 |
| 消息投递实时性 | 毫秒级。具体由consumer轮训间隔时间决定 | 毫秒级。支持pull、push两种模式,延时通常在毫秒级 | 毫秒级 |
| 顺序消费 | 支持;单是一台broker宕机后,就会产生消息乱序 | 支持;在顺序消息场景下,消费失败时消费队列将会暂停 | 支持;但如果一个消费失败,此消息的顺序会被打乱 |
| 定时消息 | 不支持 | 开源版本仅支持定时Level | 不支持 |
| 事务消息 | 不支持 | 支持 | 不支持 |
| Broker端消息过滤 | 不支持 | 支持,通过tag过滤,类似子topic | 不支持 |
| 消息查询 | 不支持 | 支持,根据MessageId查询,支持根据MessageKey查询 | 不支持 |
| 消息失败重试 | 不支持 | 支持,offset存储在broker中 | 支持 |
| 消息重新消费 | 支持;通过修改offset来重新消费 | 支持;按照时间来重新消费 | |
| 发送端负载均衡 | 可自由指定 | 可自由指定 | 需要单独loadbalancer支持 |
| 消费并行度 | 跟分区数一致 | 顺序消费:与分区数一致;乱序消费:消费服务器的消费线程数之和 | 镜像模式下其实也是从master消费 |
| 消费方式 | consumer pull | consumer pull/broker push | broker push |
| 批量发送 | 支持,默认producer缓存、压缩,然后批量发送 | 不支持 | 不支持 |
| 消息清理 | 指定文件保存时间,过期删除 | 指定文件保存时间,过期删除 | 可用内存少于40%(默认),触发gc。gc时找到相邻的两个文件,合并right文件到left |
| 访问权限控制 | 无 | 无 | 类似数据库,需要配置用户名密码 |
| 系统维护 | Scala语言开发,维护成本高 | Java语言开发,维护成本低 | Erlang语言开发,维护成本高 |
| 部署依赖 | Zookeeper | nameserver | Erlang环境 |
| 管理后台 | 官方不提供,第三方开源管理工具可使用,不用重新开发 | 官方提供,rocketmq-console | 官方提供,rabbitmqadmin |
| 优点 | 1. 在高吞吐、低延迟、高可用、集群热扩展、集群容错上有非常好的表现;2. producer端提供缓存、压缩功能,可节省性能,提高效率。3. 提供顺序消费能力;4. 提供多种客户端语言支持;5. 生态完善,在大数据处理昂面有大量配套设施。 | 1. 在高吞吐、低延迟、高可用上有非常好的表现,消息堆积时,性能也很好。2. API、系统设计都更加适应业务处理场景。3. 支持多种消费方式。4.支持broker消息过滤;5.支持事务;6. 提供消息顺序消费能力:consumer可以水平扩展,消费能力很强;7. 集群规模在50台左右,单日处理消息上百亿;经理过大数据量的考验,比较稳定可靠。 | 1. 在高吞吐量、高可用上较前两者有所不足;2. 支持多种客户端语言,支持AMQP协议;3. 由于Erlang语言的特性,性能也比较好;使用RAM模式时,性能很好。4. 管理界面较丰富,在互联网公司也有较大规模的应用。 |
| 缺点 | 1. 消费集群数目受分区数目限制;2. 单机topic多时,性能会明显降低;3. 不支持事务; | 1. 相比于Kafka,使用者较少,生态不够完善;消息堆积、吞吐率上也有所不足;2. 不支持主从自动切换,master失效后,消费者要一定时间才能感知到;3. 客户端只支持Java | 1. Erlang语言难度较大,集群不支持动态扩展;2. 不支持事务、消息吞吐能力有限;3. 消息堆积时,性能会明显降低。 |
Kafka
适用于可靠性要求较高的业务场景。
RabbitMQ
队列特性和文档都很丰富,性能和分布式能力稍弱,中小规模场景可选。
RocketMQ
适用于可靠性要求较高的业务场景。
Spring Cloud Stream
基于Redis,Rabbit,Kafka实现的消息微服务,简单声明模型用以在Spring Cloud应用中收发消息。
数据库
RDBMS vs NoSQL
| RDBMS | NoSQL | 备注 | |
|---|---|---|---|
| 数据库原理 | 完全支持 | 部分支持 | RDBMS有关系数据论作为基础,而NoSQL没有统一的理论基础。 |
| 数据规模 | 大 | 超大 | RDBMS很难实现横向扩展,纵向扩展空间也比较有限,性能会随着数据规模的增大而降低。NoSQL可以很容易通过添加更多设备来支持更大规模的数据。 |
| 数据库模式 | 固定 | 灵活 | RDBMS需要定义数据库模式,严格遵守数据定义和相关约束条件。NoSQL不存在数据库模式,可以自由灵活定义并存储各种不同类型的数据。 |
| 查询效率 | 快 | 可以实现高效简单查询,但不具备高度结构化查询等特性,复杂查询性能不尽如人意。 | RDBMS借助于索引机制可以实现快速查询(包括记录查询和范围查询)。很多NoSQL数据库没有面向复杂查询的索引,虽然NoSQL可以使用MapReduce来加速查询,但在复杂查询方面,性能仍然不如RBDMS。 |
| 一致性 | 强一致性 | 弱一致性 | RDBMS严格遵守事务ACID模型,可以保证事务强一致性。很多NoSQL数据库放松了对事务ACID四性的要求,而是遵守BASE模型,保证最终一致性。 |
| 数据完整性 | 容易实现 | 很难实现 | 任何一个RDBMS都可以很容易实现数据完整性,比如通过主键或非空约束来实现,通过主键、外键来实现参照完整性,通过约束或触发器来实现用户自定义完整性。但NoSQL数据库无法实现。 |
| 扩展性 | 一般 | 好 | RDBMS很难实现横向扩展,纵向扩展空间也比较有限,性能会随着数据规模的增大而降低。NoSQL在设计之初就充分考虑了横向扩展的需求,可以很容易通过添加廉价设备实现扩展。 |
| 可用性 | 好 | 很好 | RDBMS在任何时候都以保证数据一致性为优先目标,其次才是优化系统性能。随着数据规模的增大,RBDMS为了保证严格的一致性,只能提供相对较弱的可用性。大多数NoSQL都能提供较高的可用性。 |
| 标准化 | 是 | 否 | RDBMS已经标准化(SQL)。NoSQL还没有行业标准,不同的NoSQL数据库有自己的查询语言,很难规范应用接口。 |
| 技术支持 | 高 | 低 | RDBMS经理了几十年的发展,已经非常成熟,Oracle等大厂都可以提供很好的技术支持。NoSQL在技术支持方面仍然处于起步阶段,还不成熟明确罚有力的技术支持。 |
| 可维护性 | 复杂 | 复杂 | RDBMS需要专门的数据库管理员(DBA)维护。NoSQL数据库虽然没有RDBMS复杂,也难以维护。 |
| 产品名称 | 特点 | |
|---|---|---|
| 列存储 | Hbase, Cassandra, Hypertable | 按列存储数据,最大的特点是方便存储结构化和半结构化数据,方便做数据压缩。针对某一列或者某几列的查询有非常大的IO优势。 |
| 文档存储 | MongoDB, CouchDB | 文档存储一般用类似json的存储格式,内容是文档类型的。这样就有机会对某些字段简历索引,实现关系数据库的某些功能。 |
| key-value存储 | Redis, Memcache | 可以通过key快速查询到其对应的value。一般来说,存储不管value的格式,照单全收。 |
| 图存储 | Neo4J, FlockDB, InfoGrid | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且涉及使用不方便。 |
| 对象存储 | db4o, Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| xml数据库 | Berkeley DB, BaseX | 高效的存储XML数据,并支持xml的内部查询语法,如:XQuery, Xpath |
事务
事务的基本要素(ACID)
原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏。比如A向B转账,不可能A扣了钱,B却没收到。隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
事务的并发问题
脏读
脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据。
不可重复读
不可重复读:事务A多次读取同一数据,事务B在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。
幻读
幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
二阶段提交(2PC)
两阶段提交(2PC)是 Oracle Tuxedo 系统提出的XA分布式事务协议的其中一种实现方式。
XA协议中有两个重要角色:
- 事务协调者
- 事务参与者
第一阶段
正常情况
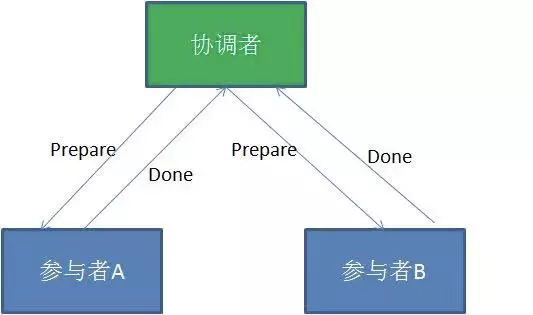
- 事务协调者的节点会首先向所有的参与者节点发送
Prepare(预备)请求。 - 在接到 Prepare(预备) 请求之后,每一个参与者节点会各自执行与事务有关的数据更新,写入
Undo Log和Redo Log。 - 参与者执行成功,暂时不提交事务,向事务协调节点返回
done(完成)消息。 - 进入第二阶段
出错时

如果某个事务参与者反馈失败消息,说明该节点的本地事务执行不成功,必须回滚。
- 事务协调者的节点会首先向所有的参与者节点发送
Prepare(预备)请求; - 在接到 Prepare(预备) 请求之后,每一个参与者节点会各自执行与事务有关的数据更新,写入
Undo Log和Redo Log; - 参与者执行失败,
返回失败消息; - 协调者
中断事务;
中断事务
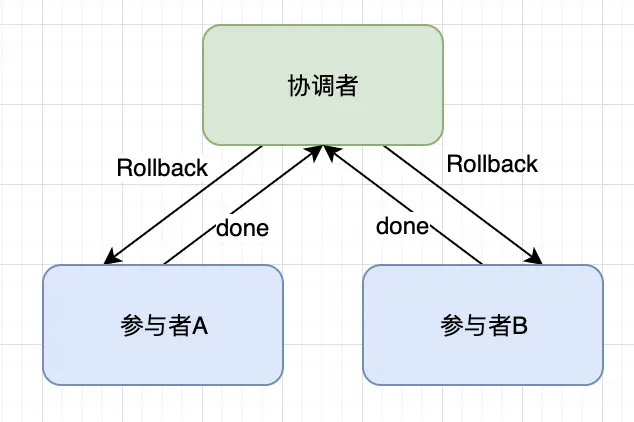
任何一个参与者向协调者反馈了 No 响应,或者在等待超时之后,协调者尚无法接收到所有参与者的反馈响应,那么就会中断事务。
- 发送回滚请求: 协调者向所有参与者节点发出
Rollback请求; - 事务回滚: 参与者收到Rollback请求之后,会利用其在阶段一记录的
Undo log来执行事务回滚操作,并在完成回滚之后释放在整个事务执行期间占用的资源; - 反馈事务回滚结果:参与者在完成事务回滚之后,向协调者发送
Ack消息; - 协调者
中断事务;
第二阶段
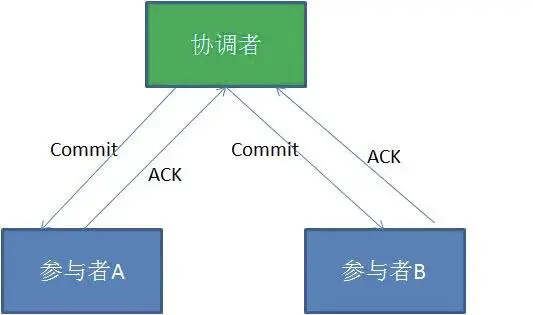
- 如果事务协调者在之前所收到都是正向返回,那么它将会向所有事务参与者发出
Commit请求。 - 接到Commit请求之后,事务参与者节点会各自进行本地的事务提交
commit,并释放锁资源。当本地事务完成提交后,将会向事务协调者返回ACK消息。 - 当事务协调者接收到所有事务参与者的“ACK”反馈,整个分布式事务完成。
缺点:
效率低:两阶段提交涉及多次节点间的网络通信,通信时间长!且在整个过程中,所有节点都处于阻塞状态,所有节点所持有的资源(例如数据库数据,本地文件等)都处于锁定状态;单点故障:由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题);数据不一致:在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据不一致性的现象。
三阶段提交(3PC)

CanCommit阶段
- 事务询问: 协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应;
- 响应反馈: 参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No;
PreCommit阶段
协调者根据参与者的反应情况来决定是否可以进行事务的PreCommit操作。
根据响应情况,有以下两种可能。
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行。
发送预提交请求:协调者向参与者发送PreCommit请求,并进入Prepared阶段。事务预提交:参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。响应反馈:如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
发送中断请求: 协调者向所有参与者发送abort请求。中断事务: 参与者收到来自协调者的abort请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
doCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况。
执行提交
发送提交请求: 协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。事务提交: 参与者接收到doCommit请求之后,执行正式的事务提交commit。并在完成事务提交之后释放所有事务资源。响应反馈: 事务提交完之后,向协调者发送Ack响应。完成事务: 协调者接收到所有参与者的ack响应之后,完成事务。
中断事务
协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
发送中断请求: 协调者向所有参与者发送abort请求;事务回滚: 参与者接收到abort请求之后,利用其在阶段二记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源;反馈结果: 参与者完成事务回滚之后,向协调者发送ACK消息;中断事务: 协调者接收到参与者反馈的ACK消息之后,执行事务的中断;
2PC与3PC的区别
相对于2PC,3PC主要解决的单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit,而不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题,因为,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作,这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
MySQL
MySQL事务隔离级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 | 备注 |
|---|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 | |
| 不可重复读(read-committed) | 否 | 是 | 是 | 写数据只会锁住相应行 |
| 可重复读(repeatable-read) | 否 | 否 | 是 | 如果检索条件有索引,默认加锁方式是next-key锁;如果没有索引,更新时会锁住整张表 |
| 串行化(serializable) | 否 | 否 | 否 | 读写数据都会锁住整张表 |
修改事务隔离级别1
set session transaction isolation level read uncommitted;
MyISAM与InnoDB的区别
| InnoDB | MyISAM | |
|---|---|---|
| 事务 | 支持 | 不支持 |
| 锁支持 | 行级锁 | 表级锁 |
| MVCC | 支持 | 不支持 |
| 外键 | 支持 | 不支持 |
| 全文索引 | 不支持 | 支持 |
| 崩溃恢复 | 支持 | 不支持 |
MVCC: Multi-Version Concurrency Control,多版本并发控制。是指在使用READ COMMITTD、REPEATABLE READ这两种隔离级别的事务执行普通的SEELCT操作时访问记录的版本链的过程,这样可以使不同事务的读-写、写-读操作并发执行,从而提升系统性能。
同一份数据临时保存多个版本的一种方式,进而实现并发控制。
不可重复读 (READ COMMITTD): 在每一次进行 SELECT 操作前都会生成一个ReadView;可重复读 (REPEATABLE READ):只在第一次进行 SELECT 操作前生成一个ReadView,之后的查询操作都重复这个ReadView就好了。
InnoDB锁机制
- 共享锁(读锁):不堵塞,多个用户可以同时读一个资源,互不干扰。
- 排他锁(写锁):会阻塞其他的读锁和写锁,这样可以只允许一个用户进行写入,防止其他用户读取正在写入的资源。
InnoDB是基于索引来完成行锁。
例:select * from tab_with_index where id = 1 for update;for update可以根据条件来完成行锁锁定,并且id是有索引键的列。如果id不是索引键那么InnoDB将完成表锁。
InnoDB日志
日志种类
- 错误日志:记录出错信息,也记录一些警告信息或者正确的信息。
- 查询日志:记录所有对数据库请求的信息,不论这些请求是否得到了正确的执行。
- 慢查询日志:设置一个阈值,将运行时间超过该值的所有SQL语句都记录到慢查询的日志文件中。
- 二进制日志:记录对数据库执行更改的所有操作。
- 中继日志:中继日志也是二进制日志,用来给slave库恢复。
- 事务日志:重做日志(redo)和回滚日志(undo)。
binlog日志格式
- Statement: 每一条会修改数据的sql都会记录在binlog中;
- Row: 不记录sql语句上下文相关信息,仅保存哪条记录被修改;
- Mixedlevel: 是以两种level混合使用。一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog。
备份
mysqldump
xtranbackup
慢查询
- 监控工具:
zabbix,lepus - show profile: 服务器上所有执行语句会记录执行时间,存到临时表中。
- show status: 会返回一些计数器,可以推测出哪些操作代价较高或者消耗时间多。
- show processlist: 观察是否有大量线程处于不正常的状态或特征。
- explain: 执行计划。
分区表
- 分区表工作原理
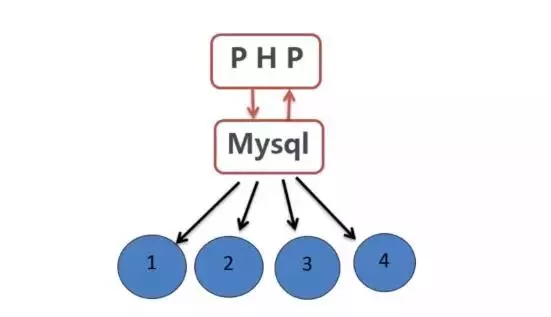
对用户而言,分区表是一个独立的逻辑表,但是底层MySQL将其分成了多个物理子表,这对用户来说是透明的,每一个分区表都会使用一个独立的表文件。
创建表时使用partition by子句定义每个分区存放的数据,执行查询时,优化器会根据分区定义过滤那些没有需要的数据的分区,这样只需要查询数据所在分区即可。
分库分表
分库分表工作原理: 通过一些HASH算法或者工具实现将一张数据表垂直或者水平进行物理切分。
- 水平分表
- 垂直分表
MySQL主从复制

- 在Slave服务器上执行
start slave命令开启主从复制开关,开始进行主从复制。 - 此时,Slave服务器的
IO线程会通过在master上已经授权的复制用户权限请求连接Master服务器,并请求从执行binlog日志文件中的指定位置之后开始发送binlog日志内容。 - Master服务器接收来自Slave服务器的IO线程的请求后,负责复制的IO线程会根据Slave服务器的IO线程请求的信息
分批读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给Slave端的IO线程。返回的信息中除了binlog日志内容外,还有在Master服务器端记录的IO线程。返回的信息中除了binlog中的下一个指定更新位置。 - 当Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的
Relay Log(即中继日志)文件(Mysql-relay-bin.xxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容。 - Slave服务器端的
SQL线程会实时检测本地Relay Log中IO线程新增的日志内容,然后及时把Relay LOG文件中的内容解析成sql语句,并在自身Slave服务器上按解析SQL语句的位置顺序执行应用这样sql语句,并在relay-log.info中记录当前应用中继日志的文件名和位置点。
Oracle
SQL Server
Redis
支持的数据类型
- String
- Hash
- List
- Set
- SortedSet
- HyperLogLog
- Geo
- Pub/Sub
Redis持久化
RDB (全量持久化)
RDB 持久化机制,是对 Redis 中的数据执行周期性的持久化;RDB更适合做冷备
优点:
- 会生成多个数据文件,每个数据文件分别都代表了某一时刻Redis里面的数据,很适合做冷备。完整的数据运维设置定时任务,定时同步到远端的服务器。
- RDB对Redis的性能影响非常小,同步数据的时候只是fork了一个子进程去做持久化,数据恢复速度比AOF快。
缺点:
- RDB都是快照文件,都是默认五分钟甚至更久的时间才会生成一次,这意味着你这次同步到下次同步这中间五分钟的数据都很可能全部丢失掉。
- 还有就是RDB在生成数据快照的时候,如果文件很大,客户端可能会暂停几毫秒甚至几秒。
AOF (增量持久化)
AOF 机制对每条写入命令作为日志,以 append-only 的模式写入一个日志文件中,因为这个模式是只追加的方式,所以没有任何磁盘寻址的开销,速度非常快,类似Mysql中的binlog。AOF更适合做热备。
两种机制全部开启的时候,Redis在重启的时候会默认使用AOF去重新构建数据,因为AOF的数据是比RDB更完整的。
优点:
- AOF是一秒一次去通过一个后台的线程fsync操作,最多丢这一秒的数据。
- AOF在对日志文件进行操作的时候是以append-only的方式去写的,他只是追加的方式写数据,写入性能惊人,文件也不容易破损。
- AOF通过可读的方式记录日志的,这样的特性适合做灾难性数据误删除的紧急恢复。
缺点:
- AOF备份的文件比RDB大。
- AOF开启后,Redis支持写的QPS会比RDB支持写的要低。
Redis集群
主从复制
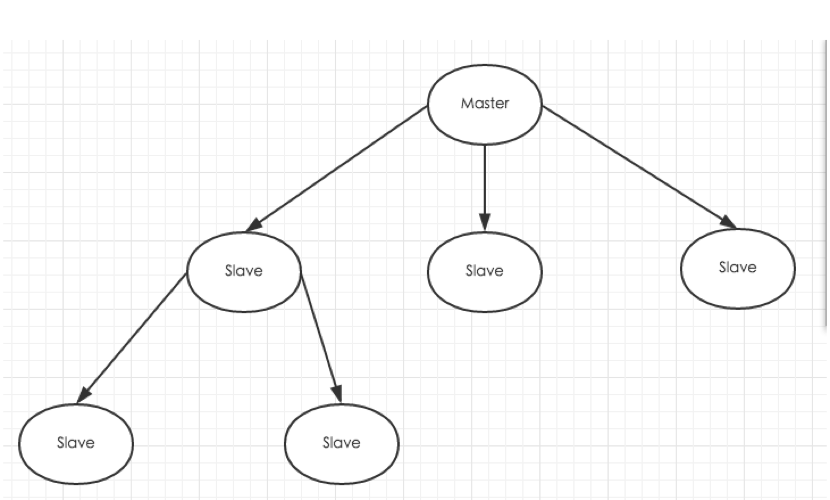
主从复制主要实现了数据的多机备份以及对于读操作的负载均衡和简单的故障恢复。
从节点作用: 一旦主节点宕机,从节点作为主节点的备份可以随时顶上来。扩展主节点的读能力,分担主节点读压力。
缺陷:
- 一旦主节点宕机,从节点晋升成主节点,同时需要修改应用方的主节点地址,还需要命令所有从节点 去复制新的主节点,整个过程
需要人工干预。 - 主节点的
写能力和存储能力均受单机的限制。 - 原生复制的弊端在早期的版本中也会比较突出,比如:Redis复制中断后,从节点会发起 psync。此时如果同步不成功,则会进行全量同步,主库执行全量备份的同时,可能会造成毫秒或秒级的卡顿。
全量同步:

增量同步:
Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
同步策略:
- 主从刚刚连接的时候,进行全量同步;
- 全同步结束后,进行增量同步。当然,slave在任何时候都可以发起全量同步。redis策略是,首先尝试进行增量同步,如不成功,则进行全量同步。
如果多个Slave断线了,需要重启的时候,因为只要Slave启动,就会发送sync请求和主机全量同步,当多个同时出现的时候,可能会导致Master IO剧增导致宕机。
建议开启master主服务器的持久化功能,避免出现master重启后,数据无法恢复;
Redis Sentinal(哨兵模式)
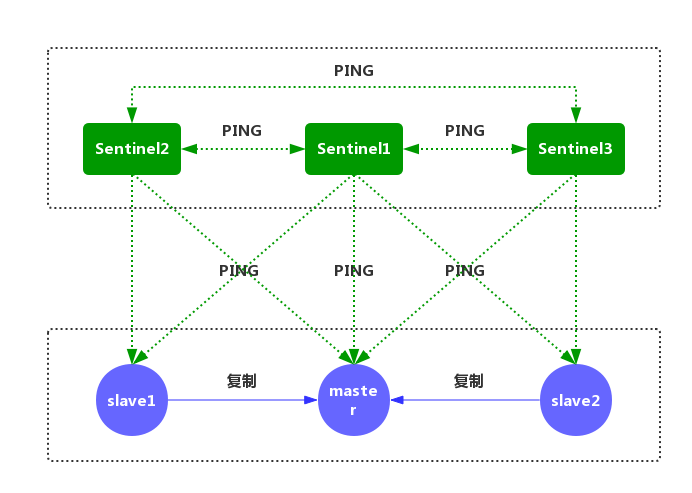
实现原理:
- 每个Sentinel以每秒钟一次的频率,向它所知的主服务器、从服务器以及其他Sentinel实例发送一个PING命令。
- 如果一个实例(instance)距离最后一次有效回复PING命令的时间超过down-after-milliseconds 所指定的值,那么这个实例会被 Sentinel 标记为主观下线。
- 如果一个主服务器被标记为主观下线,那么正在监视这个主服务器的所有Sentinel节点,要以每秒一次的频率确认主服务器的确进入了主观下线状态。
- 如果一个主服务器被标记为主观下线,并且有足够数量的 Sentinel(至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断,那么这个主服务器被标记为客观下线。
- 在一般情况下,每个 Sentinel 会以每10秒一次的频率,向它已知的所有主服务器和从服务器 发送INFO命令。当一个主服务器被 Sentinel 标记为客观下线时,Sentinel 向下线主服务器的所有从服务器发送INFO命令的频率,会从10秒一次改为每秒一次。
- Sentinel 和其他 Sentinel 协商主节点的状态,如果主节点处于SDOWN状态,则投票自动选出新的主节点。将剩余的从节点指向新的主节点进行数据复制。
- 当没有足够数量的 Sentinel 同意主服务器下线时,主服务器的客观下线状态就会被移除。当 主服务器重新向 Sentinel 的PING命令返回有效回复时,主服务器的主观下线状态就会被移除。
Redis Sentinal: 在复制的基础上,哨兵实现了自动化故障恢复。
缺陷: 写操作无法负载均衡,存储能力受单机限制。
Redis Cluster
Redis Cluster: 解决了写操作无法负载均衡以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
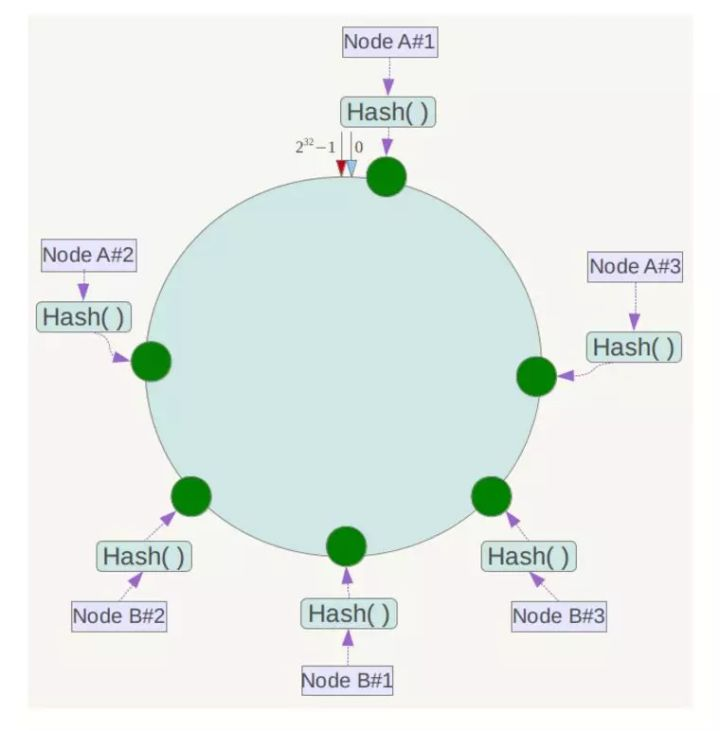
一致性hash

一致性哈希可以很好的解决稳定性问题,可以将所有的存储节点排列在首尾相接的Hash环上,每个 key在计算Hash后会顺时针找到临接的存储节点存放。而当有节点加入或退出时,仅影响该节点在 Hash环上顺时针相邻的后续节点。
虚拟节点
为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
淘汰策略
noeviction: 不删除策略, 达到最大内存限制时, 直接返回错误信息;allkeys-lru: 所有key通用,优先删除最近最少使用(less recently used, LRU) 的 key;volatile-lru: 只限于设置了expire的部分; 优先删除最近最少使用(less recently used, LRU) 的key;allkeys-random: 所有key通用,随机删除一部分key;volatile-random: 只限于设置了expire的部分,随机删除一部分key;volatile-ttl: 只限于设置了expire的部分,优先删除剩余时间(time to live, TTL) 短的key;
Memcache
Memcache 特点
- 处理请求时使用多线程异步 IO 的方式,可以合理利用 CPU 多核的优势,性能非常优秀;
- 功能简单,使用内存存储数据;
- 对缓存的数据可以设置失效期,过期后的数据会被清除;
- 失效的策略采用延迟失效,就是当再次使用数据时检查是否失效;
- 当容量存满时,会对缓存中的数据进行剔除,剔除时除了会对过期 key 进行清理,还会按 LRU 策略对数据进行剔除。
Memcache 缺点
- key 不能超过 250 个字节;
- value 不能超过 1M 字节;
- key 的最大失效时间是 30 天;
- 只支持 K-V 结构,不提供持久化和主从同步功能;
MongoDB
缓存常见问题
缓存雪崩
缓存雪崩是指缓存在同一时间同时失效,造成大量请求直接打到数据库上,导致数据库被打死。
解法:
在批量往Redis存数据的时候,把每个Key的失效时间都加个随机值就好了,这样可以保证数据不会在同一时间大面积失效。1
setRedis(Key,value,time + Math.random() * 10000);
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,我们数据库的 id 都是1开始自增上去的,如发起为id值为-1的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据库。
解法:
- 对请求参数加校验,不合法的参数直接代码Return;
- 自动将不存在的key添加到缓存中(value=null),有效时间可以设短点儿;
- Nginx上也可以加请求阈值判断,将单秒内发起这么多次请求的IP拉黑;
- 布隆过滤器(BloomFilter):利用高效的数据结构和算法快速判断出Key是否在数据库中存在,不存在直接return;存在就去查了DB刷新KV再return;
缓存击穿
缓存击穿是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库。
解法:
- 可设置热点数据永不过期;
- 加互斥锁;
分布式锁
Redis分布式锁
分布式锁要确保以下四个条件:
互斥性:在任意时刻,只有一个客户端能持有锁;不会发生死锁:即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁;具有容错性:只要大部分的Redis节点正常运行,客户端就可以加锁和解锁;加锁和解锁必须是同一个客户端:客户端自己不能把别人加的锁给解了;
1 | public class RedisTool { |
Redis集群分布式锁(RedLock)
- 获取当前时间的毫秒数
T1。 - 按顺序依次向
N个Redis节点执行获取锁的操作。这个获取锁的操作基于Redis单节点获取锁的过程相同。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还需要一个超时时间,它应该远小于锁的过期时间。客户端向某个Redis节点获取锁失败后,应立即尝试下一个Redis节点。这里失败包括Redis节点不可用或者该Redis节点上的锁已经被其他客户端持有。 - 计算整个获取锁过程的总耗时。即当前时间减去第一步记录的时间。计算公司为
T2=now()- T1。如果客户端从大多数Redis节点(>N/2 +1)成功获取到锁。并且获取锁总共消耗的时间小于锁的过期时间(即T2<expireTime)。则认为客户端获取锁成功,否则,认为获取锁失败; - 如果获取锁成功,需要重新计算锁的过期时间。它等于最初锁的有效时间减去第三步计算出来获取锁消耗的时间,即
expireTime - T2; - 如果最终获取锁失败,那么客户端立即向所有Redis节点发起释放锁的操作。
虽然说RedLock算法可以解决单点Redis分布式锁的安全性问题,但如果集群中有节点发生崩溃重启,还是会对锁的安全性有影响的。
具体出现问题的场景如下:
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
- 客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住);
- 节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了;
- 节点C重启后,客户端2锁住了C, D, E,获取锁成功;
这样,客户端1和客户端2同时获得了锁(针对同一资源)。针对这样场景,解决方式也很简单,也就是让Redis崩溃后延迟重启,并且这个延迟时间大于锁的过期时间就好。这样等节点重启后,所有节点上的锁都已经失效了。也不存在以上出现2个客户端获取同一个资源的情况了。
相比之下,RedLock安全性和稳定性都Redis单节点锁好很多,但要说完全没有问题不是。例如,如果客户端获取锁成功后,如果访问共享资源操作执行时间过长,导致锁过期了,后续客户端获取锁成功了,这样在同一个时刻又出现了2个客户端获得了锁的情况。
所以针对分布式锁的应用的时候需要多测试。服务器台数越多,出现不可预期的情况也越多。如果客户端获取锁之后,在上面第三步发生了GC得情况导致GC完成后,锁失效了,这样同时也使得同一时间有2个客户端获得了锁。
如果系统对共享资源有非常严格要求得情况下,还是建议需要做数据库锁方案来补充。如飞机票或火车票座位得情况。对于一些抢购获取,针对偶尔出现超卖,后续可以人为沟通置换得方式采用分布式锁得方式没什么问题,因为可以绝大部分保证分布式锁的安全性。
数据库分布式锁
基于数据库表
比如要对某个方法加锁,创建一张锁表,添加如下字段: 方法名,时间戳,方法名字段有唯一性索引。
当需要锁住某个方法时,往该表中插入一条相关的记录。如果有多个请求同时提交到数据库,数据库会保证只有一个操作可以成功,那么操作成功的那个线程就获得了该方法的锁。
基于数据库排他锁
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。其他没有获取到锁的就会阻塞在上述select语句上,可能的结果有2种,在超时之后获取到了锁,在超时之前仍未获取到锁。
获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,释放锁connection.commit()。
存在的问题:主要是性能不高和sql超时的异常。
Zookeeper分布式锁
基于Zookeeper临时有序节点实现的分布式锁: 每个客户端对某个方法加锁时,在zookeeper上与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。
判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。
当释放锁的时候,只需将这个瞬时节点删除即可。
服务注册/发现
| Nacos | Eureka | Consul | Etcd | Zookeeper | |
|---|---|---|---|---|---|
| 一致性协议 | CP + AP | AP | CP | CP | CP |
| 健康检查 | TCP/HTTP/MySQL/Client Beat | Client Beat | TCP/HTTP/gRPC/cmd | Keep Alive | Keep Alive |
| 负载均衡策略 | 权重/metadata/selector | Ribbon | Fabio | ||
| 雪崩保护 | 有 | 有 | 无 | 无 | 无 |
| 自动注销实例 | 支持 | 支持 | 不支持 | 支持 | |
| 访问协议 | HTTP/DNS | HTTP | HTTP/DNS | TCP | |
| 监听支持 | 支持 | 支持 | 支持 | 支持 | |
| 多数据中心 | 不支持 | 不支持 | 不支持 | ||
| 跨注册中心同步 | 支持 | 不支持 | 支持 | 不支持 | |
| Spring Cloud 集成 | 支持 | 支持 | 支持 | 支持 | 支持 |
| Dubbo 集成 | 支持 | 不支持 | 不支持 | 支持 | |
| k8s 集成 | 支持 | 不支持 | 支持 | 不支持 | |
| key-value 存储服务 | 不支持 | 支持 | 支持 | 支持 | |
| 安全 | 不支持 | acl/https | https支持(弱) | acl | |
| watch支持 | 支持long polling/大部分增量 | 全量/支持long polling | 支持long polling | 支持 |
Zookeeper
Etcd
Consul
Euraka
云端服务发现,一个基于 REST 的服务,用于定位服务,以实现云端中间层服务发现和故障转移。
API Gateway (服务网关)
Zuul
在云平台上提供动态路由,监控,弹性,安全等边缘服务的框架。Zuul 相当于是设备和 Netflix 流应用的 Web 网站后端所有请求的前门。
Spring Cloud Gateway
Kong
负载均衡
Nginx (7层)
Nginx负载均衡策略
- 轮询rr
- 加权轮询
- IP hash
- URL hash
- Fair
Haproxy (7层)
LVS (4层)
相关术语
- DS:Director Server。指的是前端负载均衡器节点。
- RS:Real Server。后端真实的工作服务器。
- VIP:向外部直接面向用户请求,作为用户请求的目标的IP地址。
- DIP:Director Server IP,主要用于和内部主机通讯的IP地址。
- RIP:Real Server IP,后端服务器的IP地址。
- CIP:Client IP,访问客户端的IP地址。
3种负载均衡模型
NAT模型

NAT模型特点:
- RS应该使用私有地址,RS的网关必须指向DIP;
- DIP和RIP必须在同一个网段内;
- 请求和响应报文都需要经过Director Server,高负载场景中,Director Server易成为性能瓶颈;
- 支持端口映射;
- RS可以使用任意操作系统;
- 缺陷:请求和响应都需经过director server,对Director Server压力会比较大;
DR模型 (Direct Route)
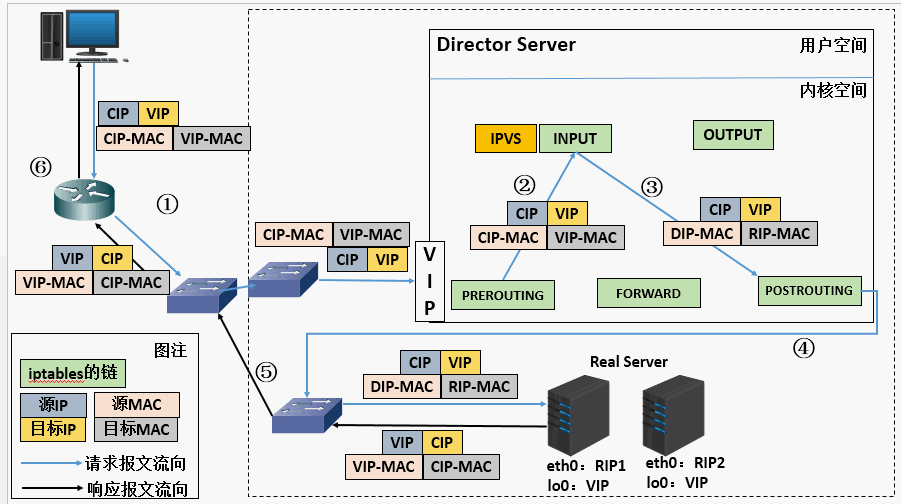
DR模型特点:
- 保证前端路由将目标地址为VIP报文统统发给Director Server,而不是RS;
- RS可以使用私有地址;也可以是公网地址,如果使用公网地址,此时可以通过互联网对RIP进行直接访问;
- RS跟Director Server必须在同一个物理网络中;
- 所有的请求报文经由Director Server,但响应报文必须不能进过Director Server;
- 不支持地址转换,也不支持端口映射;
- RS可以是大多数常见的操作系统;
- RS的网关绝不允许指向DIP(因为不允许经过director server);
- RS上的lo接口配置VIP的IP地址;
- 缺陷:RS和DS必须在同一机房中;
解决方案:
- 在前端路由器做静态地址路由绑定,将对于VIP的地址仅路由到Director Server;
- 存在问题:用户未必有路由操作权限,因为有可能是运营商提供的,所以这个方法未必实用;
- arptables:在arp的层次上实现在ARP解析时做防火墙规则,过滤RS响应ARP请求。这是由iptables提供的;
- 修改RS上内核参数(arp_ignore和arp_announce)将RS上的VIP配置在lo接口的别名上,并限制其不能响应对VIP地址解析请求;
TUN模型

Tun模型特性
- RIP、VIP、DIP全是公网地址;
- RS的网关不会也不可能指向DIP;
- 所有的请求报文经由Director Server,但响应报文必须不能进过Director Server;
- 不支持端口映射;
- RS的系统必须支持隧道;
LVS负载均衡调度算法
轮询 rr: 这种算法是最简单的,就是按依次循环的方式将请求调度到不同的服务器上,该算法最大的特点就是简单。轮询算法假设所有的服务器处理请求的能力都是一样的,调度器会将所有的请求平均分配给每个真实服务器,不管后端 RS 配置和处理能力,非常均衡地分发下去。加权轮询 wrr: 这种算法比 rr 的算法多了一个权重的概念,可以给 RS 设置权重,权重越高,那么分发的请求数越多,权重的取值范围 0 – 100。主要是对rr算法的一种优化和补充, LVS 会考虑每台服务器的性能,并给每台服务器添加要给权值,如果服务器A的权值为1,服务器B的权值为2,则调度到服务器B的请求会是服务器A的2倍。权值越高的服务器,处理的请求越多。最少链接 lc: 这个算法会根据后端 RS 的连接数来决定把请求分发给谁,比如 RS1 连接数比 RS2 连接数少,那么请求就优先发给 RS1加权最少链接 wlc: 这个算法比 lc 多了一个权重的概念。基于局部性的最少连接调度算法 lblc: 这个算法是请求数据包的目标 IP 地址的一种调度算法,该算法先根据请求的目标 IP 地址寻找最近的该目标 IP 地址所有使用的服务器,如果这台服务器依然可用,并且有能力处理该请求,调度器会尽量选择相同的服务器,否则会继续选择其它可行的服务器复杂的基于局部性最少的连接算法 lblcr: 记录的不是要给目标 IP 与一台服务器之间的连接记录,它会维护一个目标 IP 到一组服务器之间的映射关系,防止单点服务器负载过高。目标地址散列调度算法 dh: 该算法是根据目标 IP 地址通过散列函数将目标 IP 与服务器建立映射关系,出现服务器不可用或负载过高的情况下,发往该目标 IP 的请求会固定发给该服务器。源地址散列调度算法 sh: 与目标地址散列调度算法类似,但它是根据源地址散列算法进行静态分配固定的服务器资源。
LVS + Keepalived
LVS可以实现负载均衡,但是不能够进行健康检查,比如一个rs出现故障,LVS 仍然会把请求转发给故障的rs服务器,这样就会导致请求的无效性。keepalived 可以进行健康检查,而且能同时实现 LVS 的高可用性,解决 LVS 单点故障的问题。
/etc/keepalived/keepalived.conf1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39global_defs {
router_id R1 ## 本服务器的名称, 若环境中有多个keepalived时, 此名称不能一致
}
vrrp_instance VI_1 {
## 定义VRRP热备实例, 每一个keep组都不同
state MASTER ## MASTER表示主服务器
interface eth0 ## 承载VIP地址的物理接口
virtual_router_id 1 ## 虚拟路由器的ID号, 每一个keep组都不同
priority 100 ## 优先级, 数值越大优先级越高
advert_int 1 ## 通告检查间隔秒数( 心跳频率)
authentication {
## 认证信息
auth_type PASS ## 认证类型
auth_pass 123456 ## 密码字串
}
virtual_ipaddress {
192.168.100.95 ## 指定漂移地址( VIP)
}
}
virtual_server 192.168.100.95 80 {
# vip配置
delay_loop 2 ## 每隔2秒检查一次real_server状态
lb_algo wrr ## 指定lvs的调度算法
lb_kind DR ## lvs集群模式
persistence_timeout 60 ## 会话保持时间
protocol TCP ## 选择协议
real_server 192.168.100.101 80 {
## 本机地址
weight: 3 ## 服务器的权重
notify_down / etc / keepalived / check.sh ## 指定节点失效后, 采用的脚本, notify_up表示节点正常后, 采用的脚本## 健康检查方式一共有HTTP_GET |
SSL_GET | TCP_CHECK | SMTP_CHECK | MISC_CHECK这些
TCP_CHECK {
connect_timeout 10 ## 连接超时时间
nb_get_retry 3 ## 重连次数
delay_before_retry 3 ## 重连间隔时间
connect_port 80 ## 健康检查端口
}
}
}
/etc/keepalived/check.sh1
2
3
/etc/init.d/keepalived stop
echo -e "$(ip a |grep eth0 |grep inet |awk '{print $2}'|awk -F'/' '{print $1}') (httpd) is down on $(date +%F-%T)" >>/root/check_httpd.log
硬件F5, A10
Spring Cloud Ribbon
提供云端负载均衡,有多种负载均衡策略可供选择,可配合服务发现和断路器使用。
熔断器
常见限流算法
漏斗
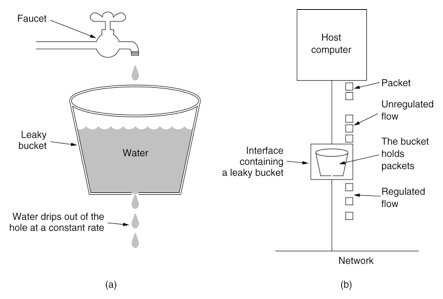
漏桶(Leaky Bucket)算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。
缺点:因为漏桶的漏出速率是固定的参数,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流突发(burst)到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。
令牌桶
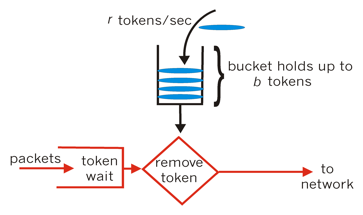
令牌桶算法(Token Bucket)和漏斗效果一样但方向相反。随着时间流逝,系统会按恒定1/QPS时间间隔(如果QPS=100,则间隔是10ms)往桶里加入Token。如果桶已经满了就不再加了,新请求来临时,会各自拿走一个Token,如果没有Token可拿了就阻塞或者拒绝服务。
优点:令牌桶的好处是可以方便的改变速度。一旦需要提高速率,只需按需提高放入桶中的令牌的速率即可。一般会定时(比如100毫秒)往桶中增加一定数量的令牌,有些变种算法则实时的计算应该增加的令牌的数量。
队列
计数器
动态流控
Hystrix
Hystrix熔断器:容错管理工具,旨在通过熔断机制控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。

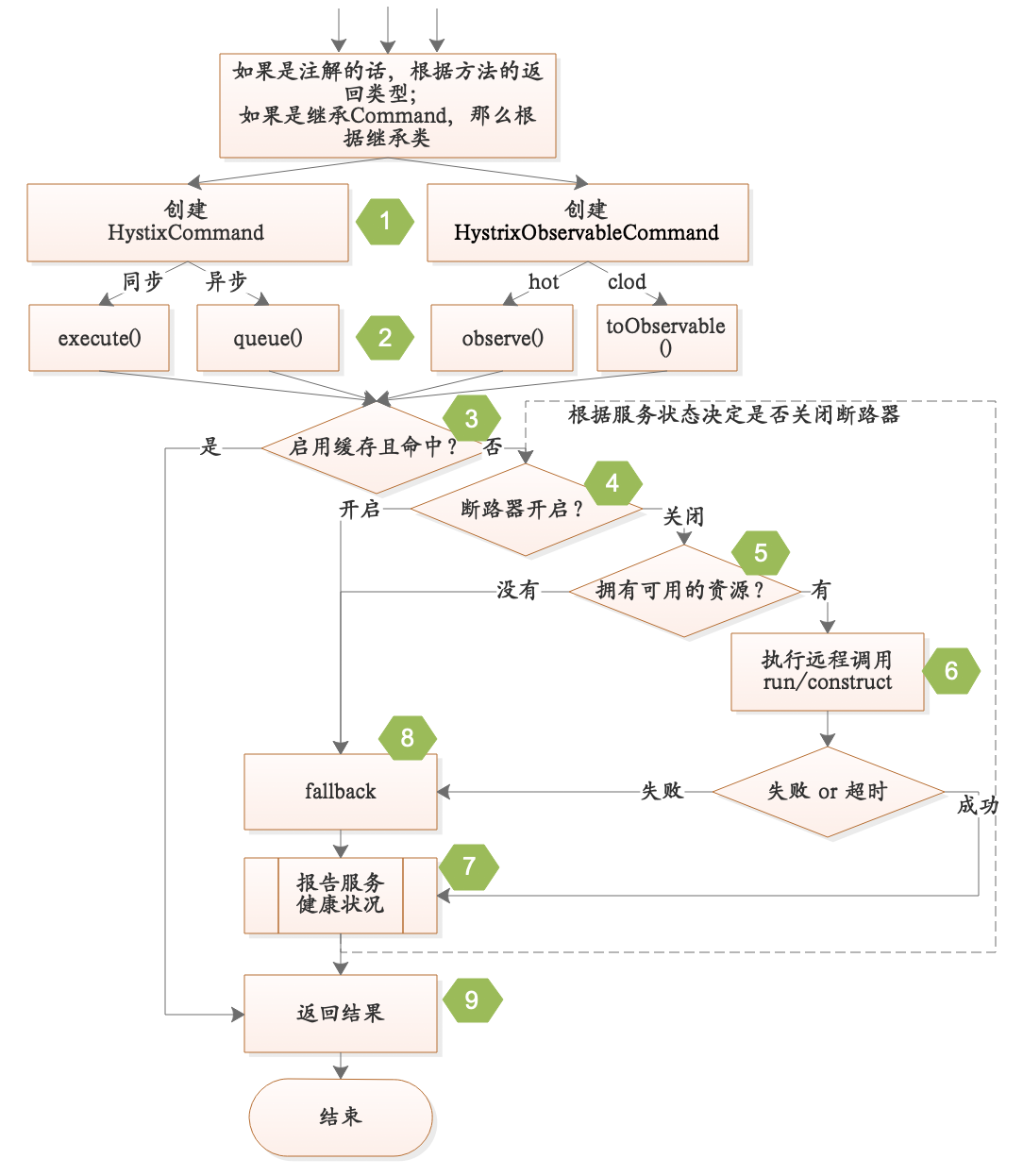
Turbine [‘tɝbaɪn]:是聚合服务器发送事件流数据的一个工具,用来监控集群下 hystrix 的 metrics 情况。
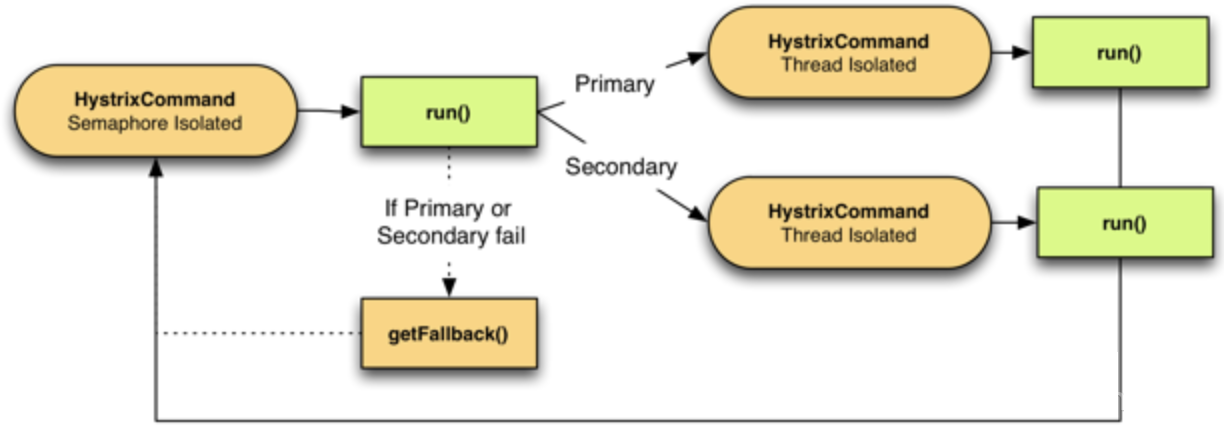
隔离模式
线程池隔离模式
线程池隔离模式:使用一个线程池来存储当前请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求先入线程池队列。这种方式要为每个依赖服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)。
信号量隔离模式
信号量隔离模式:使用一个原子计数器(或信号量)记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃该类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)。
降级
服务降级的目的保证上游服务的稳定性,当整体资源快不够了,将某些服务先关掉,待渡过难关,再开启回来。
快速模式
如果调用服务失败了,那么立即失败并返回。
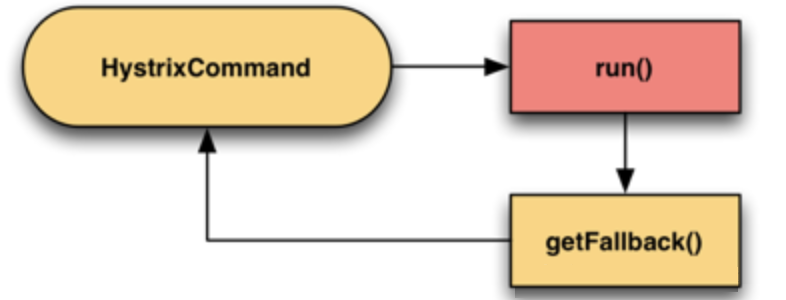
故障转移
如果调用服务失败了,那么调用备用服务,因为备用服务也可能失败,所以也可能有再下一级的备用服务,如此形成一个级联。例如:如果服务提供者不响应,则从缓存中取默认数据。
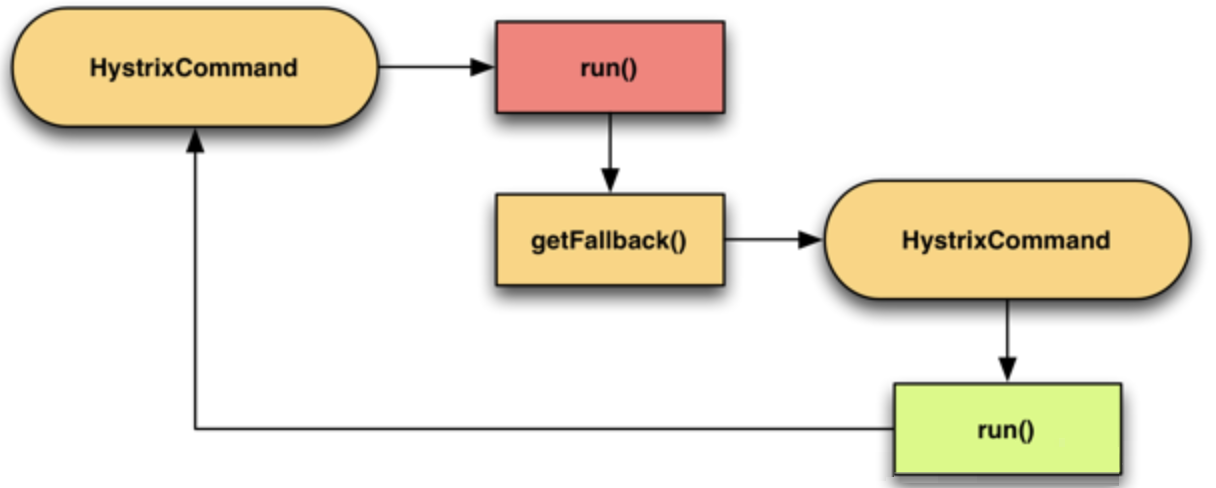
主次模式
开发中需要上线一个新功能,但为了防止新功能上线失败可以回退到老的代码,我们会做一个开关比做一个配置开关,可以动态切换到老代码功能。那么Hystrix它是使用通过一个配置来在两个command中进行切换。
Sentinel
Resilience4j
配置管理
| 功能点 | Spring Cloud Config | Apollo | Nacos |
|---|---|---|---|
| 开源时间 | 2014.09 | 2016.05 | 2018.06 |
| 配置实时推送 | 支持(Spring Cloud Bus) | 支持(Http长轮询,1s内) | 支持(Http长轮询,1s内) |
| 版本管理 | 支持(Git) | 支持 | 支持 |
| 配置回滚 | 支持(Git) | 支持 | 支持 |
| 灰度发布 | 支持 | 支持 | 待支持 |
| 权限管理 | 支持 | 支持 | 待支持 |
| 多集群 | 支持 | 支持 | 支持 |
| 多环境 | 支持 | 支持 | 支持 |
| 监听查询 | 支持 | 支持 | 支持 |
| 多语言 | 只支持Java | Go, C++, Python, PHP, Java, .NET | Python, Java, Node.JS |
| 单机部署 | Config Server + Git + Spring Cloud Bus (支持配送实时推送) | Apollo quickstart + MySQL | Nacos单节点 |
| 分布式部署 | Config Server(2) + Git + MQ 部署复杂 | Config(2) + Admin(2) + Portal(2) + MySQL 部署复杂 | Nacos(3) + MySQL 部署简单 |
| 配置格式校验 | 不支持 | 支持 | 支持 |
| 通信协议 | HTTP, AMQP | HTTP | HTTP |
| 数据一致性 | Git保证数据一致性,Config Server读取Git数据 | 数据库模拟消息队列,Apollo定时读取 | HTTP异步通知 |
| 单机读 | 7(限流所致) | 9000 | 15000 |
| 单机写 | 5(限流所致) | 1100 | 1800 |
| 3节点读 | 21(限流所致) | 27000 | 45000 |
| 3节点写 | 5(限流所致) | 3300 | 5600 |
Spring Cloud Config
2014年9月开源,Spring Cloud 生态组件,可以和Spring Cloud体系无缝整合。
Spring Cloud Config是一套配置管理工具包,让你可以把配置放到远程服务器,集中化管理集群配置,目前支持本地存储、Git以及Subversion。
Spring Cloud Bus:事件、消息总线,用于在集群(例如,配置变化事件)中传播状态变化,可与 Spring Cloud Config 联合实现热部署。
Disconf
2014年7月百度开源的配置管理中心,同样具备配置的管理能力,不过目前已经不维护了,最近的一次提交是两年前了。
Apollo
2016年5月,携程开源的配置管理中心,具备规范的权限、流程治理等特性。
携程经过生产级验证,具备高可用,配置实时生效(推拉结合),配置审计和版本化,多环境多集群支持等生产级特性,建议中大规模需要对配置集中进行治理的企业采用。
Nacos
2018年6月,阿里开源的配置中心,也可以做DNS和RPC的服务发现。
调用链监控(APM)
| CAT | Zipkin | Pinpoint | |
|---|---|---|---|
| 可视化 | 有 | 有 | 有 |
| 报表 | 非常丰富 | 少 | 中 |
| ServerMap | 简单依赖图 | 简单 | 好 |
| 埋点方式 | 侵入 | 侵入 | 不侵入(字节码增强) |
| Heartbeat支持 | 有 | 无 | 有 |
| Metric支持 | 有 | 无 | 无 |
| Java/.NET客户端支持 | 有 | 有 | 只有Java |
| Dashboard中文支持 | 好 | 无 | 无 |
| 社区支持 | 好,文档较丰富,有中文社区 | 好,文档一般,无中文社区 | 一般,文档少,无中文社区 |
| 国内案例 | 携程、点评、陆金所 | 京东 | 暂无 |
| 源头祖先 | eBay CAL | Google Dapper | Google Dapper |
Zipkin
CAT
Pinpoint
Spring Cloud Sleuth
Skywalking
日志/监控
ELK (Elasticsearch + Logstash + Kibina)
Prometheus + Grafana
Zabbix
Nagios
Spring Cloud Sleuth [sluθ]:
日志收集工具包,封装了Dapper和log-based追踪以及Zipkin和HTrace操作,为SpringCloud应用实现了一种分布式追踪解决方案。
安全
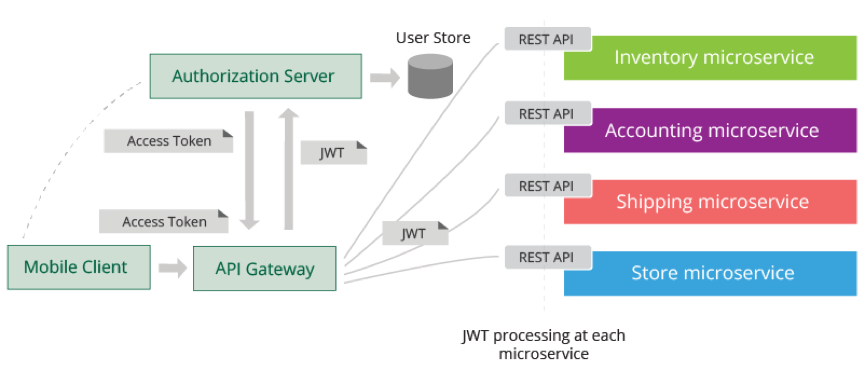
- 使用支持 OAuth 2.0 和 OpenID Connect 标准协议的授权服务器(个人建议定制自研);
- 使用 API 网关作为单一访问入口,统一实现安全治理;
- 客户在访问微服务之前,先通过授权服务器登录获取 access token,然后将 access token 和请求一起发送到网关;
- 网关获取 access token,通过授权服务器校验 token,同时做 token 转换获取 JWT token。
- 网关将 JWT Token 和请求一起转发到后台微服务;
- JWT 中可以存储用户会话信息,该信息可以传递给后台的微服务,也可以在微服务之间传递,用作认证授权等用途;
- 每个微服务包含 JWT 客户端,能够解密 JWT 并获取其中的用户会话信息。
- 整个方案中,access token 是一种 by reference token,不包含用户信息可以直接暴露在公网上;JWT token 是一种 by value token,可以包含用户信息但不暴露在公网上。
OAuth2
JWT
服务部署平台
集群资源调度系统
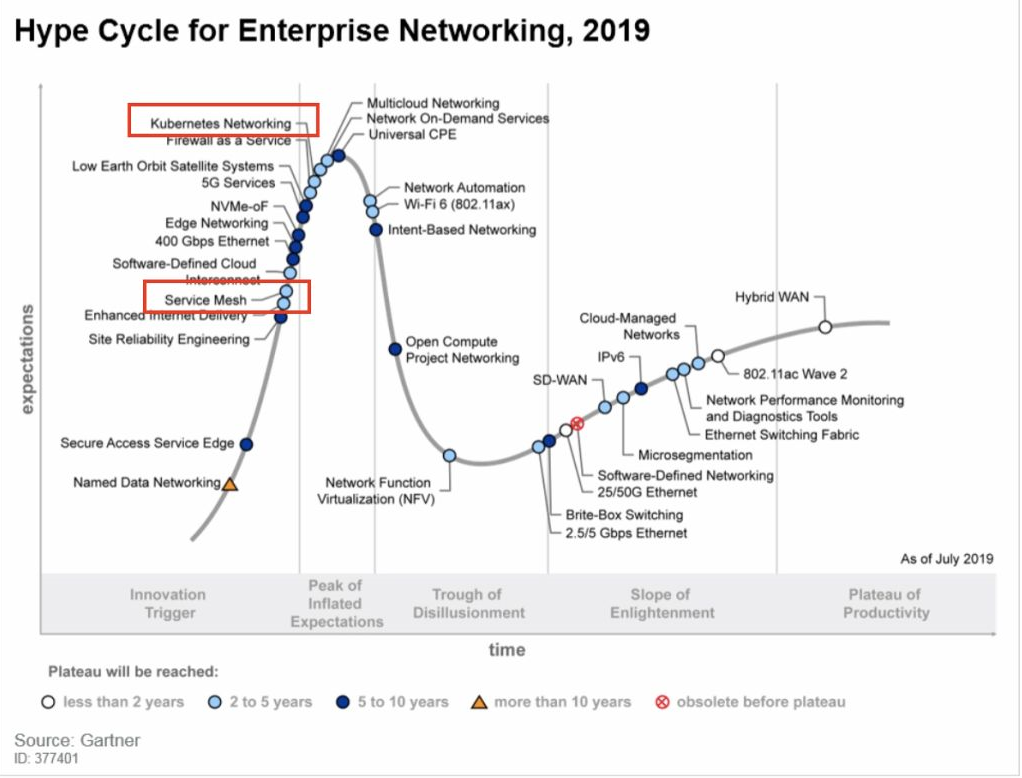
首选k8s。
Kubernetes (k8s)
Mesos
Docker Swarm
版本控制
Github
Gitlab
容器平台
Docker
AWS
阿里云
Google Cloud
镜像治理
Harbor
配置管理
Chef
Puppet
Ansible
持续集成(CI)
Jenkins
Travis CI
持续发布(CD)
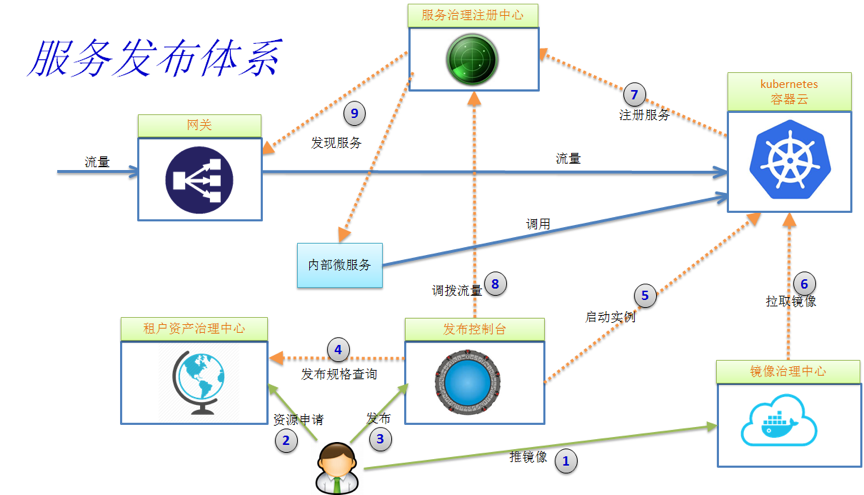
- 应用通过 CI 集成后生成镜像,用户将镜像推到镜像治理中心;
- 用户在资产治理中心申请发布,填报应用,发布和配额相关信息,然后等待审批通过;
- 发布审批通过,开发人员通过发布控制台发布应用;
- 发布系统通过查询资产治理中心获取发布规格信息;
- 发布系统向容器云发出启动容器实例指令;
- 容器云从镜像治理中心拉取镜像并启动容器;
- 容器内服务启动后自注册到服务注册中心,并保持定期心跳;
- 用户通过发布系统调用服务注册中心调拨流量,实现蓝绿,金丝雀或灰度发布等机制;
- 网关和内部微服务客户端定期同步服务注册中心上的服务路由表,将流量按负载均衡策略分发到新的服务实例上。
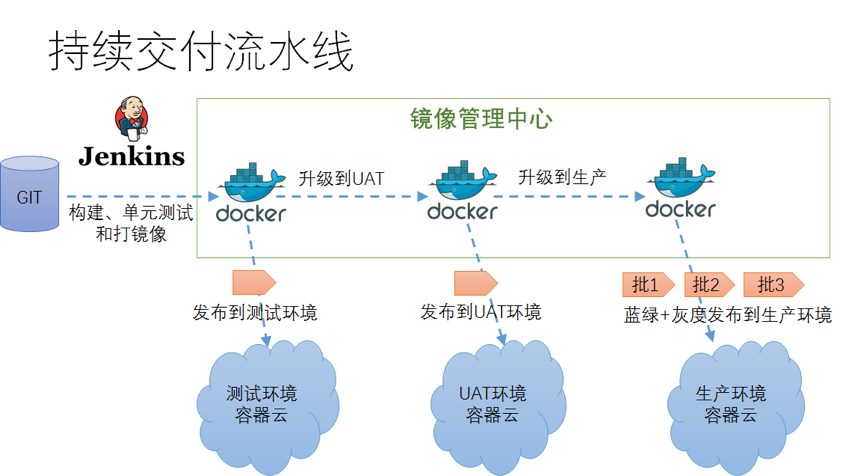
Harbor
高可用分布式锁
存储层产品
| Redis | Zookeeper | Etcd | |
|---|---|---|---|
| 一致性算法 | 无 | Paxos | Raft |
| CAP | AP | CP | CP/AP |
| 高可用 | 主从 | N+1可用 | N+1可用 |
| 接口类型 | 客户端 | 客户端 | http/gRPC |
| 实现 | setNX | createEphemeral | RESTful API |
Redis
Zookeeper
Etcd
压测工具
压测极限标准:
- 机器 load average 不超过CPU核数 * 0.6
- 服务进程CPU占用率不超过 (CPU核数 * 0.6) * 100/机器部署的服务进程数
- 网卡流量不超过网卡容量的60%(超过可能延时较大)
- 请求超时不超过十万分之一
- QPS不低于预估的85%,否则需要优化或给出合理解释
JMeter
用于对服务器、网络或对象模拟巨大的负荷,在不同压力类别下测试它们的强度,分析整体性能。
支持分布式压测。
TCPCopy
流量复制工具,能够把线上机器的流量导流到压测环境的机器上。
为营造巨大压力情况,使用Tcpdump录制请求,然后使用TCPCopy回放功能产生巨大压力。
Apache ab
基于http的方式。